Current state: Accepted
ISSUE: https://github.com/milvus-io/milvus/issues/15604
PRs:
Keywords: bulk load, import
Released: with Milvus 2.1
Authors:
Summary
Import data by a shortcut to get better performance compared with insert().
Motivation
- client calls insert() to transfer data to Milvus proxy node
- proxy split the data in do multiple parts according to sharding number of the collection
- proxy constructs a message packet for each part and send the message packets into the Pulsar service
- data nodes pull the message packets from the Pulsar service, each data node pull a packet
- data nodes persist data into segment when flush() action is triggered
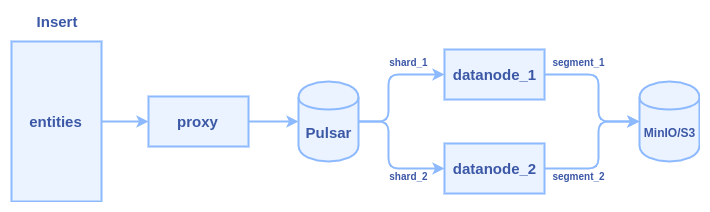
Typically, it cost several hours to insert one billion entities with 128-dimensional vectors. Lots of time is wasted in two major areas: network transmission and Pulsar management.
We can see there are at least three times network transmission in the process: 1) client => proxy 2) proxy => pulsar 3) pulsar => data node
We need a new interface to do bulk load without network bandwidth wasting and skip the Pulsar management. Brief requirements of the new interface:
- import data from JSON format files. (first stage)
- import data from Numpy format files. (first stage)
- copy a collection within one Milvus 2.0 service. (second stage)
- copy a collection from one Milvus 2.0 service to another. (second stage)
- import data from Milvus 1.x to Milvus 2.0 (third stage)
- parquet/faiss/csv files (TBD)
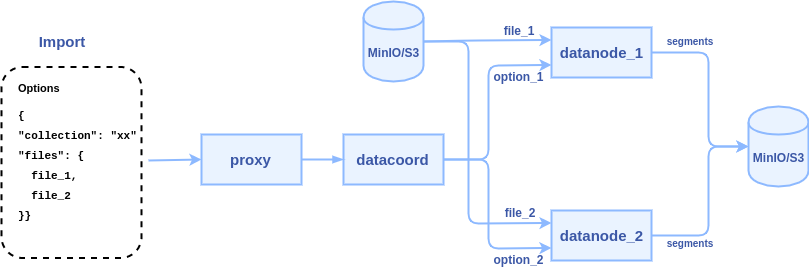
To reduce network transmission and skip Plusar management, the new interface will allow users to input the path of some data files(json, numpy, etc.) on MinIO/S3 storage, and let the data nodes directly read these files and parse them into segments. The internal logic of the process becomes:
1. client calls import() to pass some file paths to Milvus proxy node
2. proxy node passes the file paths to data coordinator node
3. data coordinator node picks a data node or multiple data nodes (according to the sharding number) to parse files, each file can be parsed into a segment or multiple segments.
SDK Interfaces
The python API declaration:
def import(collection_name, files, partition_name=None, options=None)
- collection_name: the target collection name (required)
- partition_name: target partition name (optional)
- files: a list of files with row-based format or a dict of files with column-based format (required)
row-based files: ["file_1.json", "file_2.json"]
column-based files: {"id": "id.json", "vectors": "embeddings.npy"} - options: extra options in JSON format, for example: the MinIO/S3 bucket where the files come from (optional)
{"bucket": "mybucket"}
Pre-defined format for import files
Assume we have a collection with 2 fields(one primary key and one vector field) and 5 rows:
| uid | vector |
|---|---|
| 101 | [1.1, 1.2, 1.3, 1.4] |
| 102 | [2.1, 2.2, 2.3, 2.4] |
| 103 | [3.1, 3.2, 3.3, 3.4] |
| 104 | [4.1, 4.2, 4.3, 4.4] |
| 105 | [5.1, 5.2, 5.3, 5.4] |
There are two ways to represent the collection with data files:
(1) Row-based data file, a JSON file contains multiple rows.
file_1.json:
{ {"uid": 101, "vector": [1.1, 1.2, 1.3, 1.4]}, {"uid": 102, "vector": [2.1, 2.2, 2.3, 2.4]}, {"uid": 103, "vector": [3.1, 3.2, 3.3, 3.4]}, {"uid": 104, "vector": [4.1, 4.2, 4.3, 4.4]}, {"uid": 105, "vector": [5.1, 5.2, 5.3, 5.4]},
}
Call import() to import the file:
import(collection_name="test", files=["file_1.json"])
(2) Column-based data file, each JSON file represents a column. We require the keyword "values" as a key of the field data.
In this case, there are two fields, so we create 2 JSON files:
file_1.json for the "uid" field:
{
"values": [101, 102, 103, 104, 105]
}
file_2.json for the "vector" field:
{
"values": [[1.1, 1.2, 1.3, 1.4], [2.1, 2.2, 2.3, 2.4], [3.1, 3.2, 3.3, 3.4], [4.1, 4.2, 4.3, 4.4], [5.1, 5.2, 5.3, 5.4]]
}
Call import() to import the file:
import(collection_name="test", files={"uid": "file_1.json", "vector": "file_2.json"})
We also user store vectors in a Numpy file, let's say the "vector" field is stored in file_2.npy, then we can call import():
import(collection_name="test", files={"uid": "file_1.json", "vector": "file_2.npy"})
Proxy RPC Interfaces
The declaration of import API in proxy RPC:
service MilvusService {
rpc Import(ImportRequest) returns (ImportResponse) {}
}
message ImportRequest {
common.MsgBase base = 1;
string options = 2; // options in JSON format
}
message ImportResponse {
common.Status status = 1;
repeated schema.IDs IDs = 2; // auto-generated ids for succeed chunks
uint32 succ_index = 3; // number of chunks that successfully imported
}
Datacoord RPC interfaces
The declaration of import API in datacoord RPC:
service DataCoord {
rpc Import(milvuspb.ImportRequest) (milvuspb.ImportResponse) {}
rpc CompleteImport(ImportResult) returns (common.Status) {}
}
message ImportResult {
common.Status status = 1;
schema.IDs IDs = 2; // auto-generated ids
repeated int64 segments = 3; // id array of new sealed segments
}
Datanode RPC interfaces
The declaration of import API in datanode RPC:
service DataNode {
rpc Import(milvus.ImportRequest) returns(common.Status) {}
}