Current state: Under Discussion
Keywords: HA, primary-backup, RootCoord, DataCoord, QueryCoord, IndexCoord
Released:
Summary
To achieve HA by supporting primary-backup mechanism for all Coordinators(RootCoord, DataCoord, QueryCoord, IndexCoord).
Motivation
Currently, each Milvus coordinator(coord) is a single node, so there are risks of single points of failure(SPOF). As a distributed system, Milvus needs to mitigate the impact of SPOFs and provides high available service to users. This project aims to support basic primary-backup mechanism, which is a popular high availability solution.
Public Interfaces
No public interfaces need to be added or changed. It's transparent to users.
Design Details
Key points for primary-backup mechanism
- Failure Detection: detect primary failure quickly and accurately
- Take Over & FailOver:
- The standby coord should take over the responsibility after detecting the primary coord's failure.
- All clients connected to that coord should failover and update the new coord info in memory automatically. (seems this is already supported)
- Recovery: The old master can serve as a standby after recovery.
Current start-up process
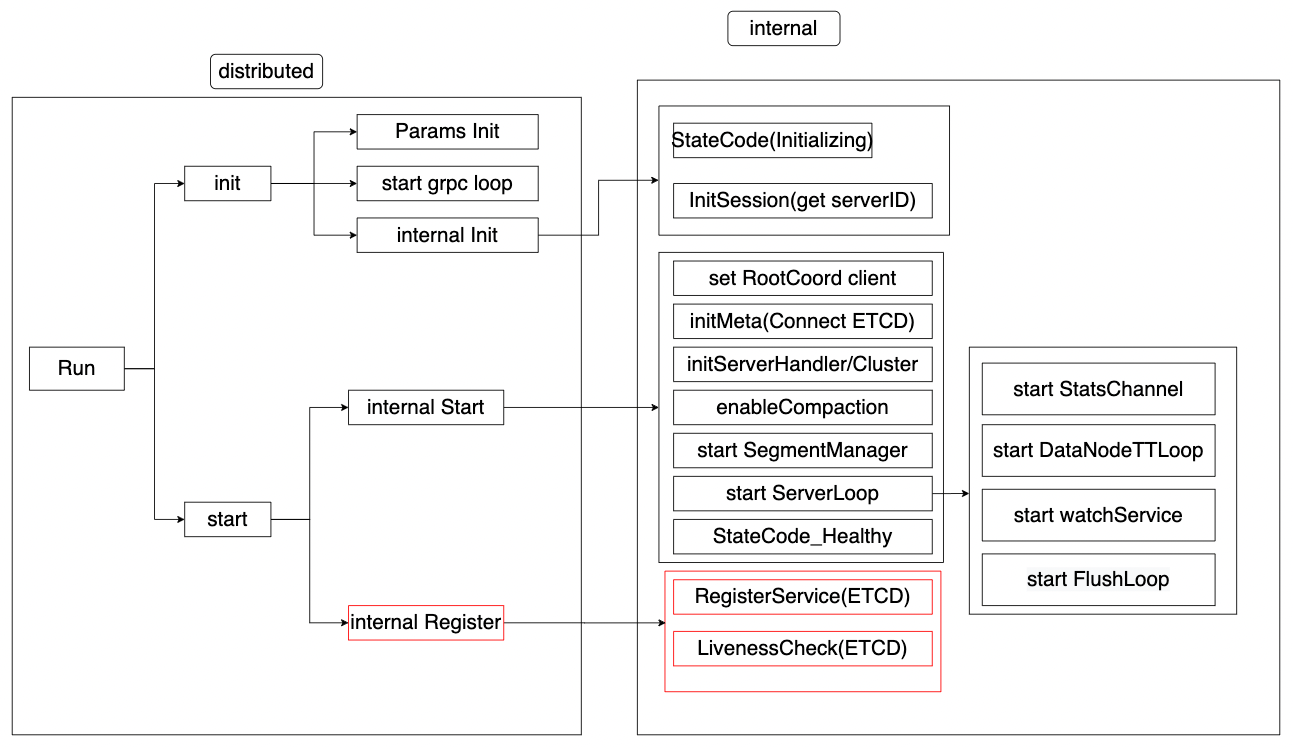
The start-up progress of a coordinator is like the graph above (take DataCoord as an example, others are very similar). Currently, each component in Milvus cluster maintains a keepAlive lease with ETCD(internal Register in the graph), and Milvus establishes service discovery based on it. Therefore, we can easily detect failure by watching the coords' key in ETCD. The design are mainly in internal register as followed.
internal Register
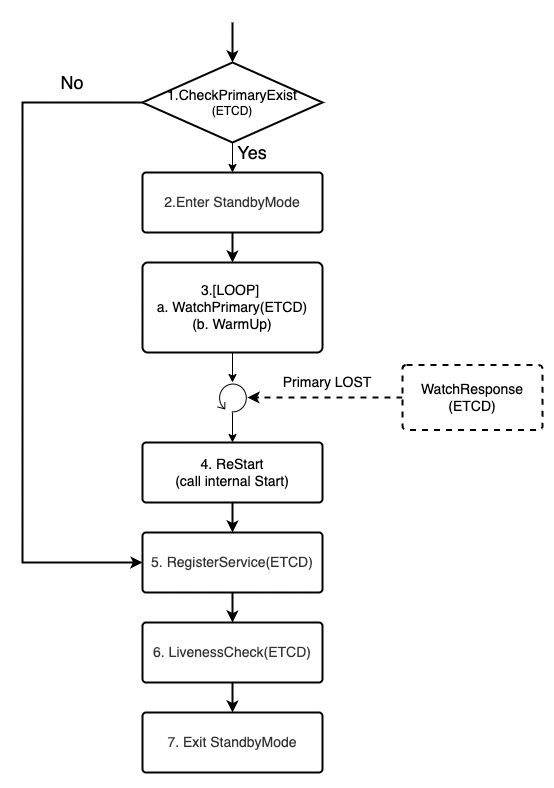
- Check if the primary service already exists. If true, go to 2. enter StandbyMode. If false, go to 5. register to ETCD as usual.
- Enter StandyMode. (We can add a new value in StateCode or define a new flag.)
- Start a loop to keep watching the primary key in ETCD. And WarmUp can do something like update the meta to accurate the Restart if necessary.
- When receiving a primary key lost WatchResponse, break the loop and Restart. Restart is to call the internal Start func.
- Register the service to ETCD as primary. (A ETCD lock may be needed in RegisterService to make sure there is only one primary in the cluster at any time.)
- Start up the LivenessCheck goroutine
- Exit StandyMode. The standby node will take over the primary role and start working.
Test Plan
Develop a cluster with primary and standby coords. Manually remove the primary coord or mock some crash in the primary coord. The standby coord should take over successfully. The cluster must keep working after a short time of partial failure. The test should be done for each kind of coords.