Current state: Accepted
ISSUE: https://github.com/milvus-io/milvus/issues/11182
PRs:
Keywords: Primary key Deduplication, KeyValue Store, Disaggregate storage and computation
Released: with Milvus 2.1
Authors: Xiaofan Luan
Summary(required)
We want to introduce a global storage to index the relationship between primary key and segment+segment offset.
The index should has the following characteristics:
1) Must be able plugin with other cloud native database, such as Dynamo, Aurora, Apache Cassandra, Apache HBase...
2) Able to scale to at least 100B entites, support 100m+ TPS/QPS
3). Ms level response time
4) Not introduce another local state to milvus component, it has to be maintained by cloud service or rely mainly on object storage and pulsar.
5) Query strong consistent data under certain Ts.
The index can be further extended to support global secondary index, as well as Full-text index in the future.
Motivation(required)
See git issue:
In many situations, Milvus need an efficient way to find the primary key location(Which Segment the primary key is in).
For example, we may want to dedup by primary key, in the write path we will need to know if the pk is already written in Milvus or not, Another case is when we want to find which segment the pk is in while execute delete, so far the delete use BloomFilter to filter out segments not related with this primary key, however the false positive may cause unnecessary delete delta logs in sealed segments.
Certain Query/Search request can also utilize the KV index. First step is to support query by pk request, it could also be used for other field indexing later on. For instance, if a collection has 3 field:
1) pk a int64 2) b string 3) c vector. The KV index should be able to help on the following Query/Search:
Query xxx where a = 1
Query xxx where a > 1 && a < 3 (That might be not efficient if pk is not the partition key)
Search xxx near [queryvector] and a > 1 && a < 1000 LIMIT 10 (use KV index to filter out some )
KV Storage can also be used to lookup the reduced result. Currently we will have to retrieve the whole entity from Segcore after local reduce and sent back to proxy, there are two problems of current design
1) it K is large and users fetch many fields, the query results will be really large, while most of the query results are not really necessary and will be dropped under global reduce.
2)all the fields in segcore has to be loaded into memory, the vector field might be too large to fit into memory. we've already support local caching, but all the storage is under columnar mode, a row based storage can better serve retrieve by id under some situations.
Public Interfaces(optional)
KV interface
Put(key, value string) error
BatchPut(kvs map[string] string) error
Delete(key string) error
BatchDelete(keys [] string)
DeleteRange(start string, end string) error
DeletePrefix(prefix string) error
Get(key string) string
BatchGet(key string[]) string[]
Scan(startKey string, endKey string) string[]
ScanPrefix(prefixKey string) string[]
Design Details(required)
1) Basic work flow

Plan1
Proxy directly interact with KV Index.
Pros : No need to worry about consistency, read always the lastest data.
Easy to implement
Cons: KV storage has to handle incremental data persistence, which means ncrem has to be maintained on
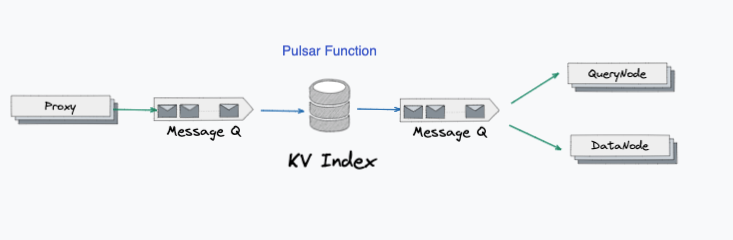
Plan2
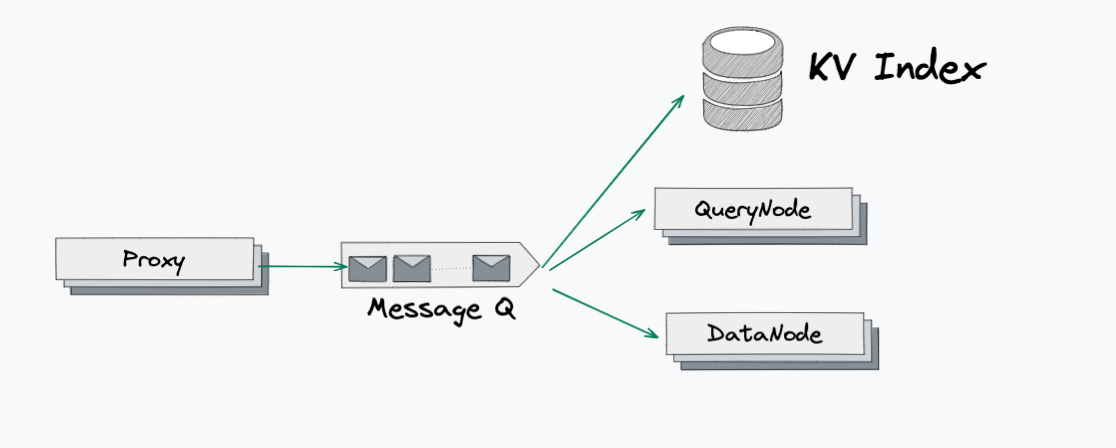
Plan3
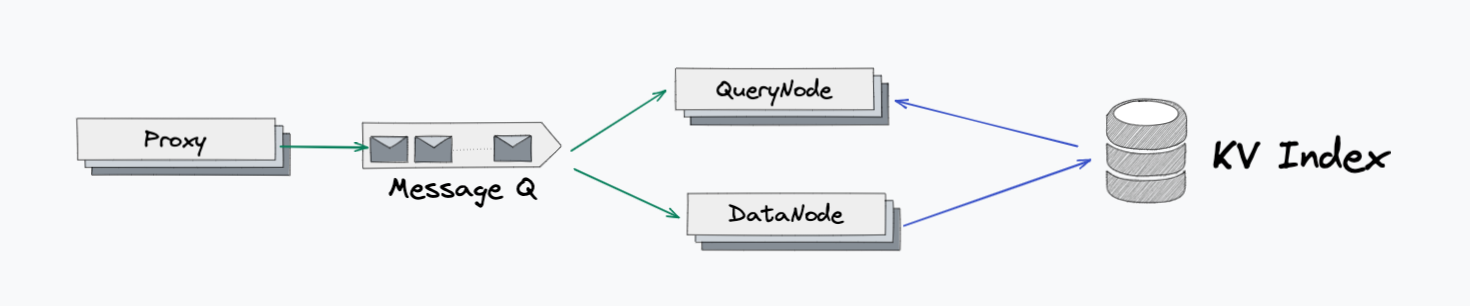
Plan4
2)What KV engine to support
we will support plugin storages, most of the storage are maintained by cloud provider or user's exist deployment. However, we still need one default implementation which can use for test.
How to maintain data persistence
How to shard data
Test Plan(required)
Rejected Alternatives(optional)
1. Use Query Api to find primary key, it need to query in each segment thus not efficient enough.
2. Use external KV service instead of implement one by our self. We plan to support external KVs such as dynamo db, Apache Cassandra and TiKV.
3.
3.