Current state: "Under Discussion"
ISSUE: #7210
PRs:
Keywords: arrow/column-based/row-based
Released: Milvus 2.0
Summary
Milvus 2.0 is a cloud-native and multi-language vector database, we use gRPC and pulsar to communicate among SDK and components.
In consideration of the data size, especially when inserting and search result returning, Milvus takes a lot of CPU cycles to do serialization and deserialization.
In this enhancement proposal, we suggest to adopt Apache Arrow as Milvus in-memory data format. Since in the field of big data, Apache Arrow has been a
factor standard for in-memory analytics. It specifies a standardized language-independent columnar memory format.
Motivation(required)
From a data perspective, Milvus mainly includes 2 data flows mainly:
- Insert data flow
- Search data flow
Insert Data Flow
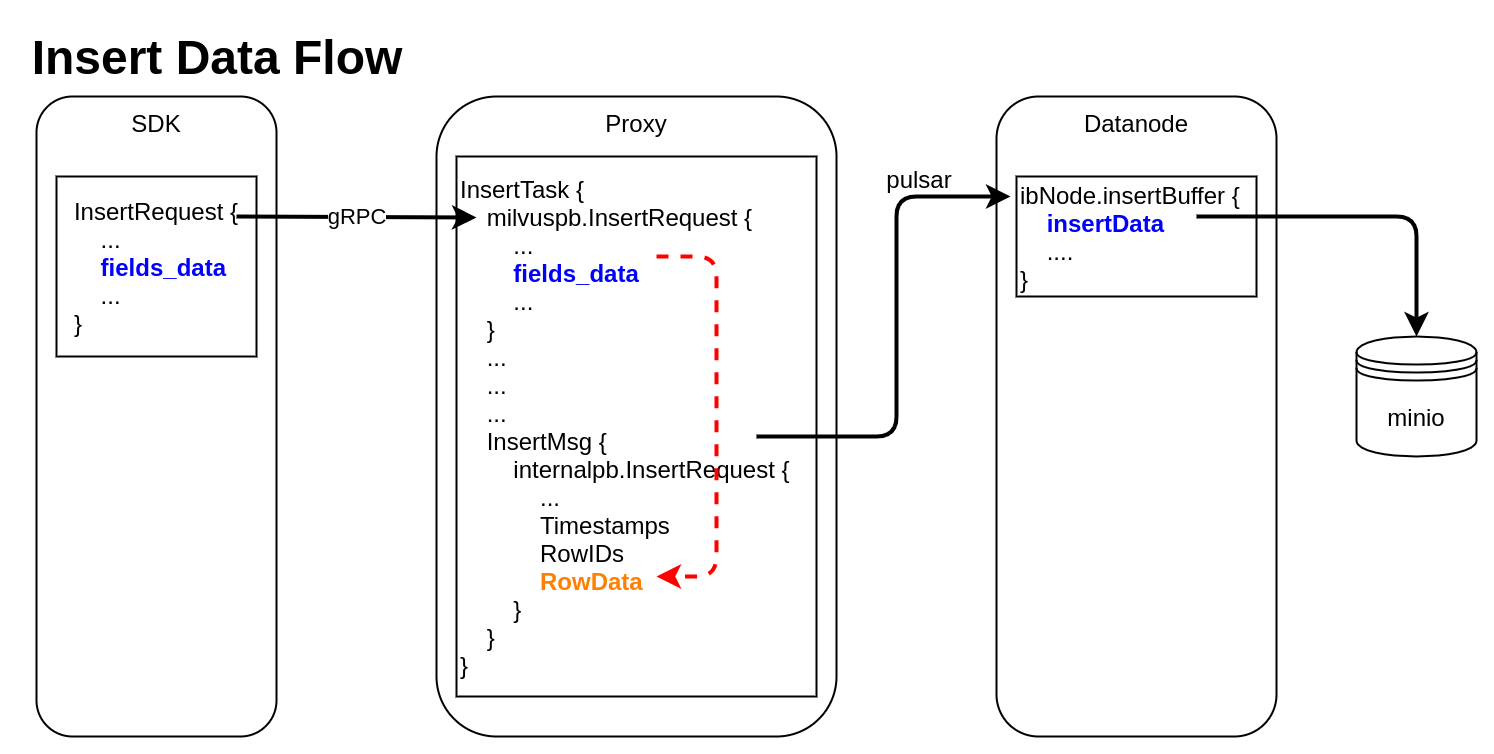
pymilvus creates a data insert request with type milvuspb.InsertRequest (client/prepare.py::bulk_insert_param)
// grpc-proto/milvus.proto message InsertRequest { common.MsgBase base = 1; string db_name = 2; string collection_name = 3; string partition_name = 4; repeated schema.FieldData fields_data = 5; // fields' data repeated uint32 hash_keys = 6; uint32 num_rows = 7; }Data is inserted into fields_data by column, schemapb.FieldData is defined as following:
// grpc-proto/schema.proto message ScalarField { oneof data { BoolArray bool_data = 1; IntArray int_data = 2; LongArray long_data = 3; FloatArray float_data = 4; DoubleArray double_data = 5; StringArray string_data = 6; BytesArray bytes_data = 7; } } message VectorField { int64 dim = 1; oneof data { FloatArray float_vector = 2; bytes binary_vector = 3; } } message FieldData { DataType type = 1; string field_name = 2; oneof field { ScalarField scalars = 3; VectorField vectors = 4; } int64 field_id = 5; }milvuspb.InsertRequest is serialized and send via gRPC
Proxy receives milvuspb.InsertRequest, creates InsertTask for it, and adds this task into execution queue (internal/proxy/impl.go::Insert)
InsertTask is executed, the column-based data stored in InsertTask.req is converted to row-based format, and saved into another internal message with type internalpb.InsertRequest (internal/proxy/task.go::transferColumnBasedRequestToRowBasedData)
// internal/proto/internal.proto message InsertRequest { common.MsgBase base = 1; string db_name = 2; string collection_name = 3; string partition_name = 4; int64 dbID = 5; int64 collectionID = 6; int64 partitionID = 7; int64 segmentID = 8; string channelID = 9; repeated uint64 timestamps = 10; repeated int64 rowIDs = 11; repeated common.Blob row_data = 12; // row-based data }rowID and timestamp are added for each row data
Datanode receives InsertMsg from pulsar channel, restore data to column-based into structure InsertData (internal/datanode/flow_graph_insert_buffer_node.go::insertBufferNode::Operate)
type InsertData struct { Data map[FieldID]FieldData // field id to field data Infos []BlobInfo }
Search Data Flow
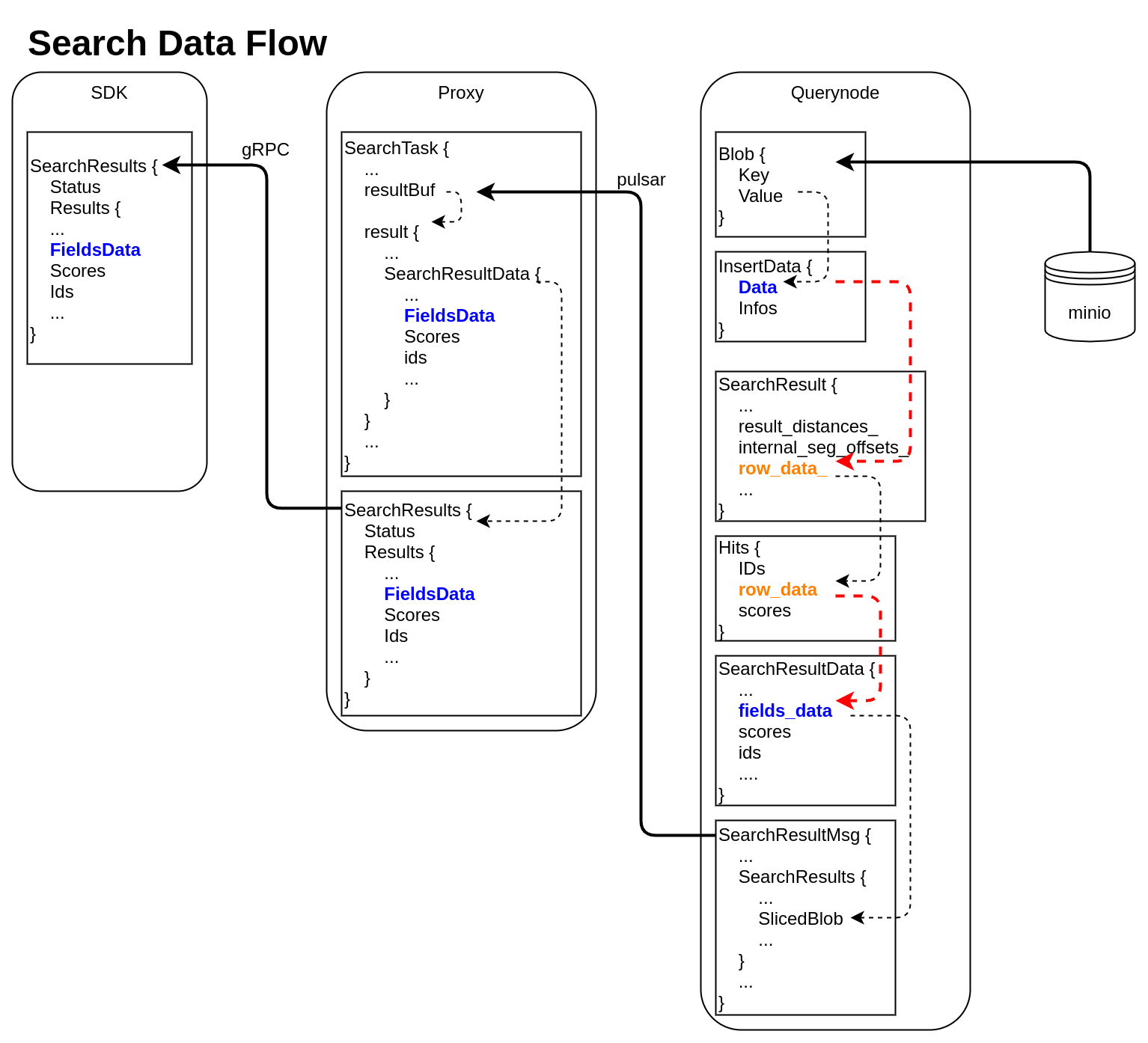
querynode reads segment's binlog files from Minio, and saves them into structure Blob (internal/querynode/segment_loader.go::loadSegmentFieldsData)
type Blob struct { Key string // binlog file path Value []byte // binlog file data }The data in Blob is deserialized, raw-data in it is saved into structure InsertData
querynode invokes search engine to get SearchResult (internal/query_node/query_collection.go::search)
// internal/core/src/common/Types.h struct SearchResult { ... public: int64_t num_queries_; int64_t topk_; std::vector<float> result_distances_; public: void* segment_; std::vector<int64_t> internal_seg_offsets_; std::vector<int64_t> result_offsets_; std::vector<std::vector<char>> row_data_; };
At this time, only "result_distances_" and "internal_seg_offsets_" of "SearchResult" are filled into data.querynode reduces all SearchResult returned by segment, fetches all other fields' data, and saves them into "row_data_" with row-based format. (internal/query_node/query_collection.go::reduceSearchResultsAndFillData)
querynode organizes SearchResult again, and save them into structure milvus.Hits
// internal/proto/milvus.proto message Hits { repeated int64 IDs = 1; repeated bytes row_data = 2; repeated float scores = 3; }Row-based data saved in milvus.Hits is converted to column-based data, and saved into schemapb.SearchResultData (internal/query_node/query_collection.go::translateHits)
// internal/proto/schema.proto message SearchResultData { int64 num_queries = 1; int64 top_k = 2; repeated FieldData fields_data = 3; repeated float scores = 4; IDs ids = 5; repeated int64 topks = 6; }schemapb.SearchResultData is serialized, encapsulated as internalpb.SearchResults, saved into SearchResultMsg, and send into pulsar channel (internal/query_node/query_collection.go::search)
// internal/proto/internal.proto message SearchResults { common.MsgBase base = 1; common.Status status = 2; string result_channelID = 3; string metric_type = 4; repeated bytes hits = 5; // search result data // schema.SearchResultsData inside bytes sliced_blob = 9; int64 sliced_num_count = 10; int64 sliced_offset = 11; repeated int64 sealed_segmentIDs_searched = 6; repeated string channelIDs_searched = 7; repeated int64 global_sealed_segmentIDs = 8; }Proxy collects all SearchResultMsg from querynodes, gets schemapb.SearchResultData by deserialization, then gets milvuspb.SearchResults by reducing, finally send back to SDK visa gRPC. (internal/proxy/task.go::SearchTask::PostExecute)
// internal/proto/milvus.proto message SearchResults { common.Status status = 1; schema.SearchResultData results = 2; }- SDK receives milvuspb.SearchResult
In above 2 data flows, we can see frequent format conversion between column-based data and row-based data (marked as RED dashed line).
If we use Arrow as all in-memory data format, we can:
- omit the serialization and deserialization between SDK and proxy
- remove all format conversion between column-based data and row-based data
- use Parquet as binlog file format, and write from arrow data directly
Public Interfaces(optional)
We will use Arrow to replace all in-memory data format used in Insert/Search/Query.
All proto definitions which are used to communicate between SDK and proxy are listed below:
- Proto changed for Insert
// internal/proto/milvus.proto
message InsertRequest {
...
- repeated schema.FieldData fields_data = 5;
+ bytes batch_record = 5;
...
}
- Proto changed for Search
// internal/proto/milvus.proto
-message PlaceholderValue {
- string tag = 1;
- PlaceholderType type = 2;
- // values is a 2d-array, every array contains a vector
- repeated bytes values = 3;
-}
-message PlaceholderGroup {
- repeated PlaceholderValue placeholders = 1;
-}
message SearchRequest {
...
- bytes placeholder_group = 6; // must
+ bytes vector_record = 6; // must
...
}
message Hits {
...
- repeated bytes row_data = 2;
+ bytes batch_record = 2;
...
}
// internal/proto/schema.proto
message SearchResultData {
...
- repeated FieldData fields_data = 3;
+ bytes batch_record = 3;
...
}
- Proto changed for Query
// internal/proto/milvus.proto
message QueryResults {
...
- repeated schema.FieldData fields_data = 2;
+ bytes batch_record = 2;
}
Design Details(required)
After this MEP, Milvus will not be compatible with previous Milvus 2.0.0-rcX, because:
- the proto format between SDK and proxy changed
- binlog file format changed
We divide this MEP into 2 stages, all compatibility changes will be achieved in Stage 1 before Milvus 2.0.0, other internal changes can be left later.
Stage 1
- Update InsertRequest in milvus.proto, change Insert to use Arrow format
- Update SearchRequest/Hits in milvus.proto, and SearchResultData in schema.proto, change Search to use Arrow format
- Update QueryResults in milvus.proto, change Query to use Arrow format
- Update Storage module to write Parquet from Arrow, or read Arrow from Parquet directly. Write one Segment into one Parquet file.
Stage 2
- Upgrade C++ Arrow module used in Storage from version 2.0.0 to 5.0.0
- Remove all internal row-based data structure, including "RowData" in internalpb.InsertRequest, "row_data" in milvuspb.Hits, "row_data_" in C++ SearchResult.
- Optimize search result flow
Test Plan(required)
Pass all CI flows
References(optional)
https://arrow.apache.org/docs/