Current state: "Under Discussion"
ISSUE: #7210
PRs:
Keywords: arrow/column-based/row-based
Released: Milvus 2.0
Summary
Milvus 2.0 is a cloud-native and multi-language vector database, we use gRPC and pulsar to communicate among SDK and components.
In consideration of the data size, especially when inserting or returning search results, Milvus takes considerable efforts to do serialization and deserialization.
In the field of big data, Apache Arrow has been a factor standard to solve this kind of problems.
Apache Arrow is a development platform for in-memory analytics. It contains a set of technologies that enable big data systems to process and move data fast.
It specifies a standardized language-independent columnar memory format for flat and hierarchical data, organized for efficient analytic operations on modern hardware.
The project is developing a multi-language collection of libraries for solving systems problems related to in-memory analytical data processing. This includes such topics as:
Zero-copy shared memory and RPC-based data movement
Reading and writing file formats (like CSV, Apache ORC, and Apache Parquet)
In-memory analytics and query processing
Motivation(required)
From data inspect, Milvus includes 2 data flows mainly:
- Insert data flow
- Search data flow
Insert Data Flow
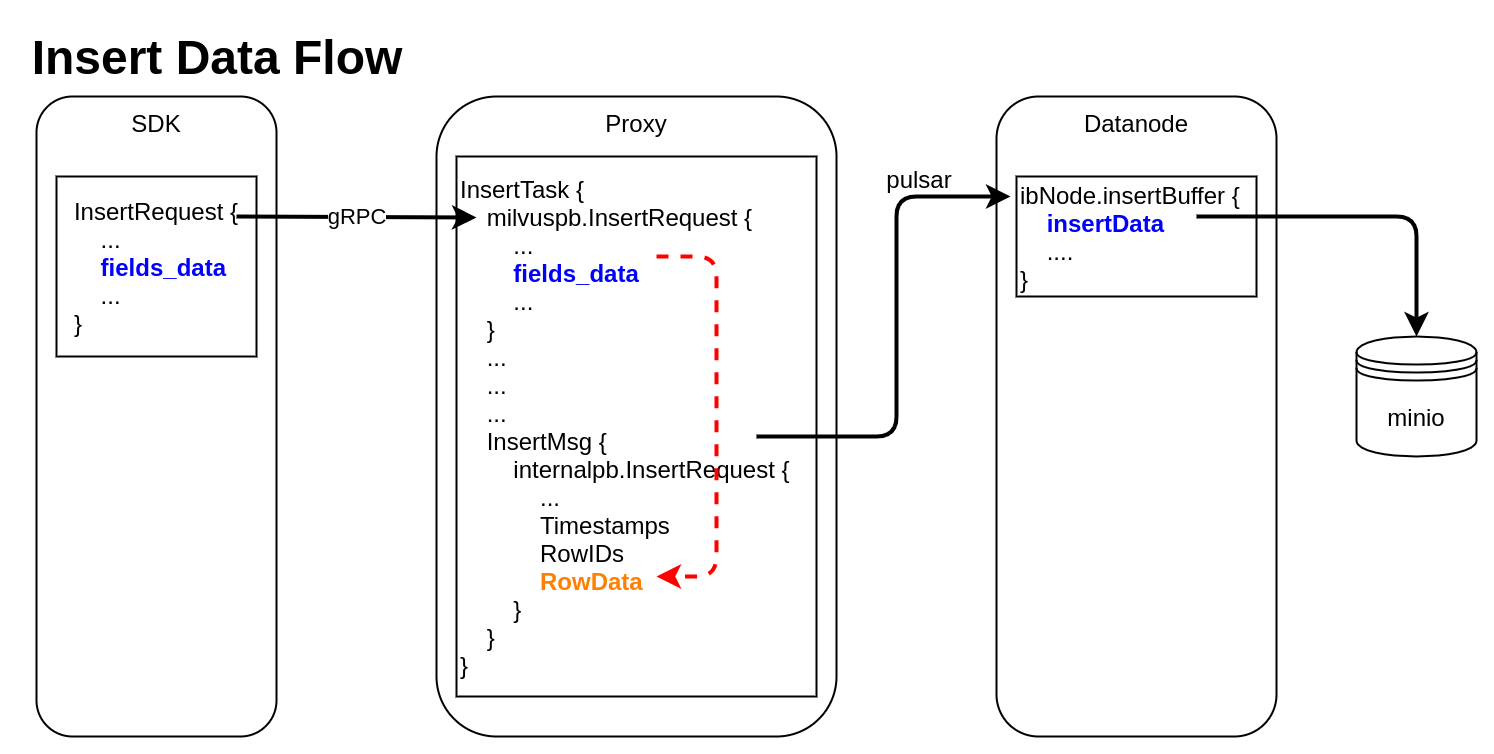
pymilvus creates a data insert request with type milvuspb.InsertRequest (client/prepare.py::bulk_insert_param)
// grpc-proto/milvus.proto message InsertRequest { common.MsgBase base = 1; string db_name = 2; string collection_name = 3; string partition_name = 4; repeated schema.FieldData fields_data = 5; // fields' data repeated uint32 hash_keys = 6; uint32 num_rows = 7; }Data is inserted into fields_data by column, schemapb.FieldData is defined as following:
// grpc-proto/schema.proto message ScalarField { oneof data { BoolArray bool_data = 1; IntArray int_data = 2; LongArray long_data = 3; FloatArray float_data = 4; DoubleArray double_data = 5; StringArray string_data = 6; BytesArray bytes_data = 7; } } message VectorField { int64 dim = 1; oneof data { FloatArray float_vector = 2; bytes binary_vector = 3; } } message FieldData { DataType type = 1; string field_name = 2; oneof field { ScalarField scalars = 3; VectorField vectors = 4; } int64 field_id = 5; }milvuspb.InsertRequest is serialized and send via gRPC
Proxy receives milvuspb.InsertRequest, creates InsertTask for it, and adds this task into execution queue (internal/proxy/impl.go::Insert)
InsertTask is executed, the column-based data stored in InsertTask.req is converted to row-based format, and saved into another internal message with type internalpb.InsertRequest (internal/proxy/task.go::transferColumnBasedRequestToRowBasedData)
// internal/proto/internal.proto message InsertRequest { common.MsgBase base = 1; string db_name = 2; string collection_name = 3; string partition_name = 4; int64 dbID = 5; int64 collectionID = 6; int64 partitionID = 7; int64 segmentID = 8; string channelID = 9; repeated uint64 timestamps = 10; repeated int64 rowIDs = 11; repeated common.Blob row_data = 12; // row-based data }rowID and timestamp are added for each row data
Datanode receives InsertMsg from pulsar channel, restore data to column-based into structure InsertData (internal/datanode/flow_graph_insert_buffer_node.go::insertBufferNode::Operate)
type InsertData struct { Data map[FieldID]FieldData // field id to field data Infos []BlobInfo }
Search Data Flow
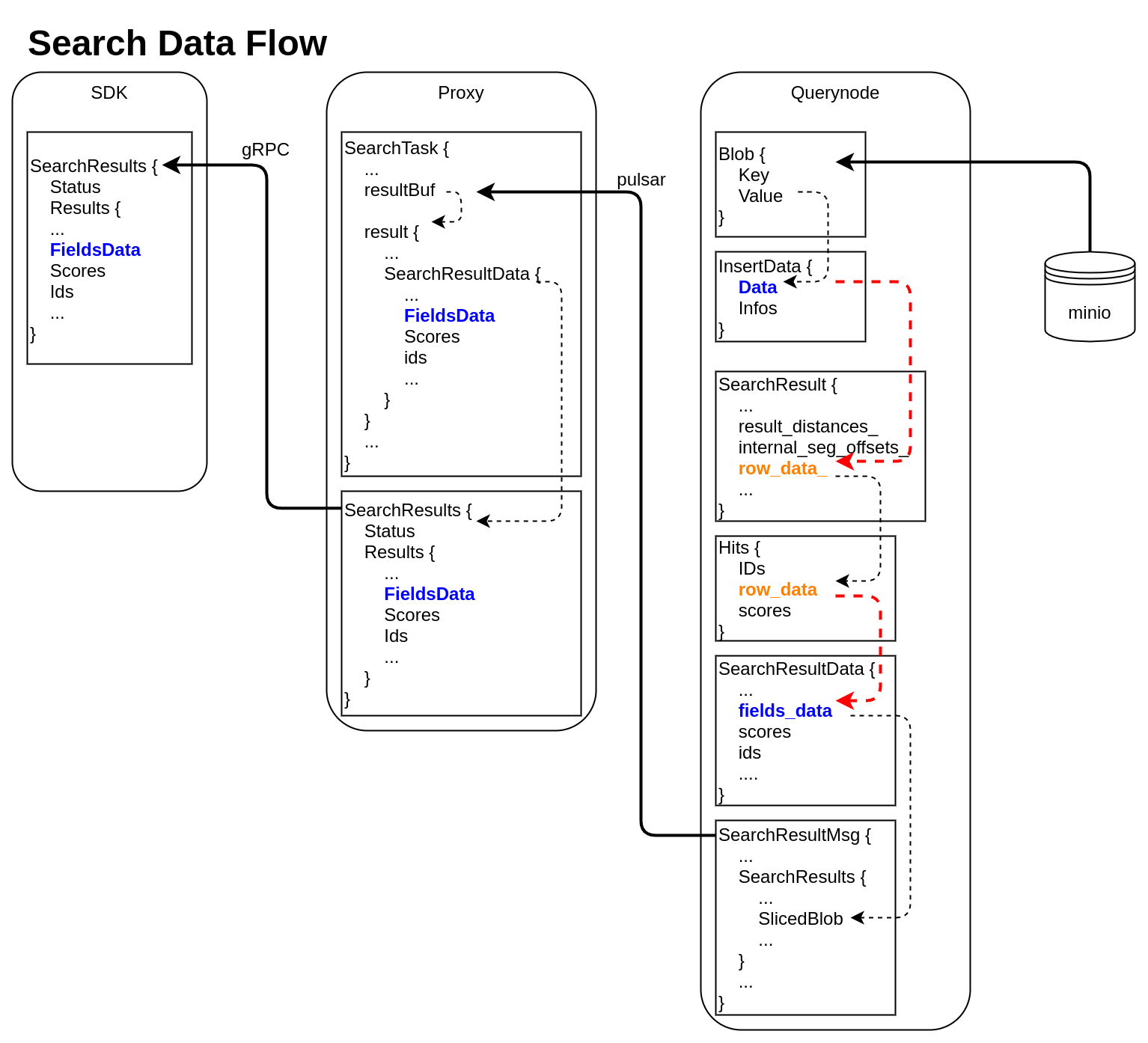
querynode reads segment's binlog files from Minio, and saves them into structure Blob (internal/querynode/segment_loader.go::loadSegmentFieldsData)
type Blob struct { Key string // binlog file path Value []byte // binlog file data }The data in Blob is deserialized, raw-data in it is saved into structure InsertData
querynode invokes search engine to get SearchResult (internal/query_node/query_collection.go::search)
// internal/core/src/common/Types.h struct SearchResult { ... public: int64_t num_queries_; int64_t topk_; std::vector<float> result_distances_; public: void* segment_; std::vector<int64_t> internal_seg_offsets_; std::vector<int64_t> result_offsets_; std::vector<std::vector<char>> row_data_; };
At this time, only "result_distances_" and "internal_seg_offsets_" of "SearchResult" are filled into data.querynode reduces all SearchResult returned by segment, fetches all other fields' data, and saves them into "row_data_" with row-based format. (internal/query_node/query_collection.go::reduceSearchResultsAndFillData)
querynode organizes SearchResult again, and save them into structure milvus.Hits
// internal/proto/milvus.proto message Hits { repeated int64 IDs = 1; repeated bytes row_data = 2; repeated float scores = 3; }Row-based data saved in milvus.Hits is converted to column-based data, and saved into schemapb.SearchResultData (internal/query_node/query_collection.go::translateHits)
// internal/proto/schema.proto message SearchResultData { int64 num_queries = 1; int64 top_k = 2; repeated FieldData fields_data = 3; repeated float scores = 4; IDs ids = 5; repeated int64 topks = 6; }schemapb.SearchResultData is serialized, encapsulated as internalpb.SearchResults, saved into SearchResultMsg, and send into pulsar channel (internal/query_node/query_collection.go::search)
// internal/proto/internal.proto message SearchResults { common.MsgBase base = 1; common.Status status = 2; string result_channelID = 3; string metric_type = 4; repeated bytes hits = 5; // search result data // schema.SearchResultsData inside bytes sliced_blob = 9; int64 sliced_num_count = 10; int64 sliced_offset = 11; repeated int64 sealed_segmentIDs_searched = 6; repeated string channelIDs_searched = 7; repeated int64 global_sealed_segmentIDs = 8; }Proxy collects all SearchResultMsg from querynodes, gets schemapb.SearchResultData by deserialization, then gets milvuspb.SearchResults by reducing, finally send back to SDK visa gRPC. (internal/proxy/task.go::SearchTask::PostExecute)
// internal/proto/milvus.proto message SearchResults { common.Status status = 1; schema.SearchResultData results = 2; }- SDK receives milvuspb.SearchResult
Public Interfaces(optional)
Briefly list any new interfaces that will be introduced as part of this proposal or any existing interfaces that will be removed or changed.
Design Details(required)
Describe the new thing you want to do in appropriate detail. This may be fairly extensive and have large subsections of its own. Or it may be a few sentences. Use judgement based on the scope of the change.
## Compatibility, Deprecation, and Migration Plan(optional)
- What impact (if any) will there be on existing users?
- If we are changing behavior how will we phase out the older behavior?
- If we need special migration tools, describe them here.
- When will we remove the existing behavior?
- upgrade to Arrow-5.0.0
- Change FillTargetEntry to column-based
- Update Storage module to write Parquet from arrow directly
Test Plan(required)
Describe in few sentences how the MEP will be tested. We are mostly interested in system tests (since unit-tests are specific to implementation details). How will we know that the implementation works as expected? How will we know nothing broke?
Rejected Alternatives(optional)
If there are alternative ways of accomplishing the same thing, what were they? The purpose of this section is to motivate why the design is the way it is and not some other way.
References(optional)
Briefly list all references