ISSUE: #1924 #3199 #4201 #4430 #4810 #5603
PRs:
Keywords: string tries hybrid search
Released:
Motivation
The data types currently supported by Milvus do not include the String type. According to the feedback in the previous issue list, the support of the String data type is expected by many users. One of the most urgent requirements of the String type is to support the primary key of the custom String type. Take the image search application as an example. In actual needs, users need to uniquely identify a picture with a string type value. The string type value can be the name of the picture, the md5 value of the picture, and so on. Since Milvus does not support the string data type, users need to make an additional int64 to string mapping externally, which reduces the efficiency and increases the maintenance cost of the entire application.
When users create a Collection, they can specify a String type Field in the Schema. The Field of the String type can of course be designated as the primary field at the same time.
In the system design, the type of string field is a variable-length character string, but a fixed size limit is set for the character string, such as 64KB, 256KB, etc. If the storage size of the string exceeds the limit value, the insertion fails.
Users can retrieve the previous field of string type according to the search/query interface. Users can add scalar filtering operations for string type Fields in search/query. The filtering operations include: "==", "!=" "<" ,"<=" ,">",">="
A piece of sample code is as follows:
from pymilvus_orm import connections, Collection, FieldSchema, CollectionSchema, DataType
>>> import random
>>> schema = CollectionSchema([
... FieldSchema("film_name", DataType.String, is_primary=True),
... FieldSchema("films", dtype=DataType.FLOAT_VECTOR, dim=2)
... ])
>>> collection = Collection("film_collection", schema)
>>> # insert
>>> data = [
... ["film_%d"+str(i) for i in range(10)],
... [[random.random() for _ in range(2)] for _ in range(10)],
... ]
>>> collection.insert(data)
>>> # search
>>> res = collection.search(data=[1.0,1.0],
anns_field="films",
param = {"metric_type":"L2"},
limit=2,
expr = "film_name != 'film_1'")
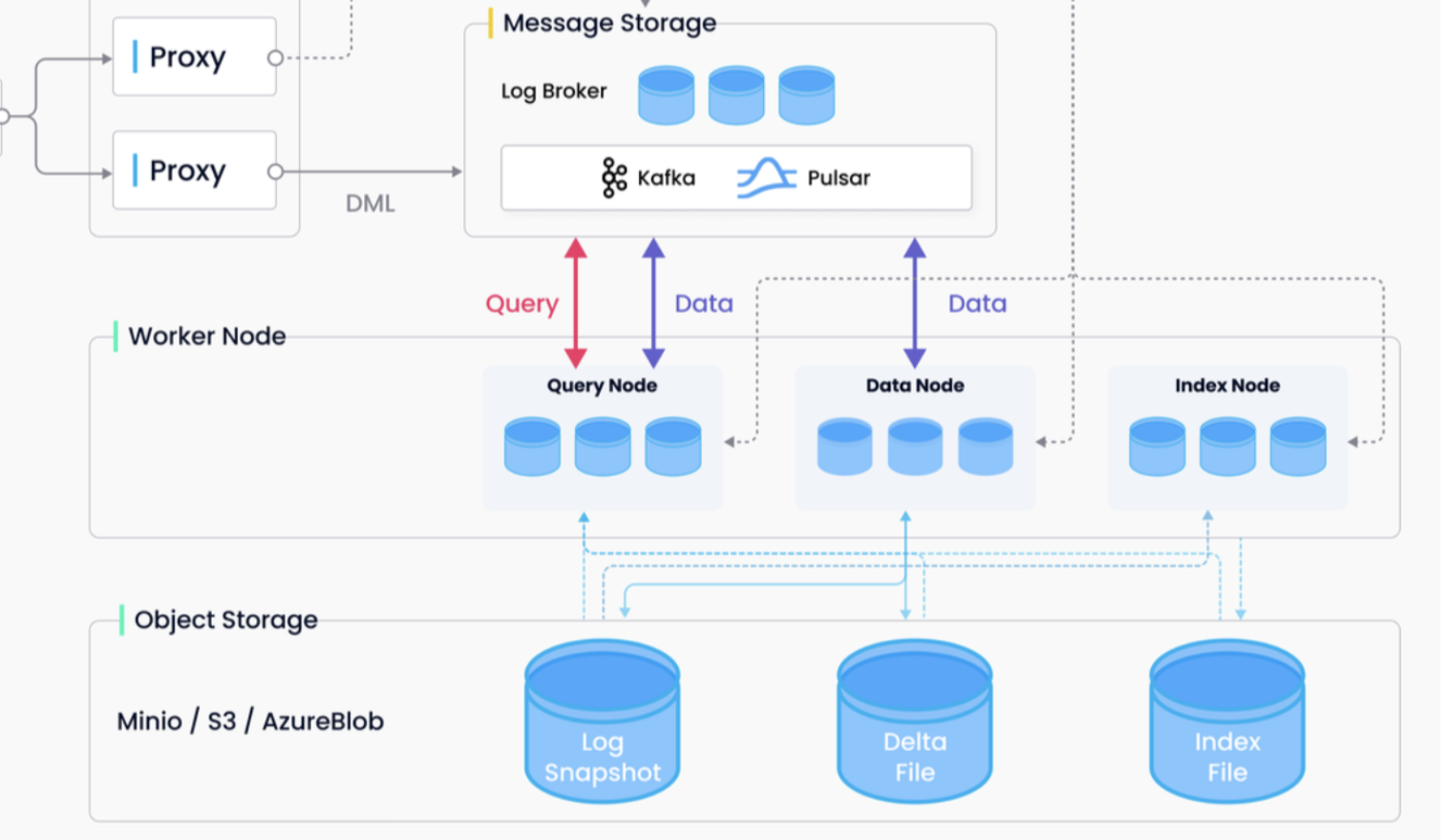
Before introducing the design scheme, let's briefly review the data flow of the milvus2.0 system.
In milvus2.0, MessageStroge is the backbone of the entire system. Milvus 2.0 implements the unified Lambda architecture, which integrates the processing of the incremental and historical data. Milvus 2.0 introduces log backfill, which stores log snapshots and indexes in the object storage to improve failure recovery efficiency and query performance.
The data model of milvus2.0 mainly includes Collection, Partition, and Segment. Collection can be logically divided into multiple Partitions, for example, we can divide different Partitions according to date. The collection is physically composed of multiple Segments. A Segment contains multiple Entities, and an Entity is equivalent to row data in a traditional database. An Entity contains multiple Field data. A Field is equivalent to a Column in a traditional database. These Fields include those specified by the Schema when the user creates the Collection, and some hidden Fields added by the system, such as timestamps.
For OLAP purposes, it is best to store information in a columnar format. Columnar storage lets you ignore all the data that doesn’t apply to a particular query because you can retrieve the information from just the columns you want. An added advantage is that, since each Field holds the same type of data, Field data can use a compression scheme selected specifically for the field data type.
In Milvus, the basic unit of reading and writing is the Field of the Segment. The basic module Storage encapsulates the reading and writing, encoding, and decoding of Field in the Object Storage. Therefore, the Storage module needs to support the String type Field.
DataNode's processing of String Field is the same as that of other Fields.
As mentioned earlier, segment data is stored by Fields. a Field is stored in multiple batches of small files. These small files and the data in it are arranged by the insertion order.
For example, Collection C1 has a field named field1. And a Segment of c1 is stored as m files. And the order of file names matters.
collection_id/partition_id/segment_id/field1/log_1 collection_id/partition_id/segment_id/field1/log_2 ... collection_id/partition_id/segment_id/field1/log_m
Query and Search are two different operations, although their parameters are very similar. For the convenience of description, we use Search to represent these two operations in the following text, unless otherwise specified.
For QueryNode, the Query requires Historical and Streaming data. Historical data can be considered Immutable, and Streaming data, as it is continuously consumed from MessageStorage, is constantly added. Therefore, in order to optimize the Search, different designs need to be adopted for the two data sources.
First, let's introduce the general processing flow of QueryNode to the Search requests.
QueryNode first determines the set of segments involved with the Search request for a Collection. The search operation is performed on each segment to obtain the sub-results, and then all the sub-results are merged into the final result. Therefore, Segment is the basic processing unit of Search operations. We need to focus on the search operation in the Segment.
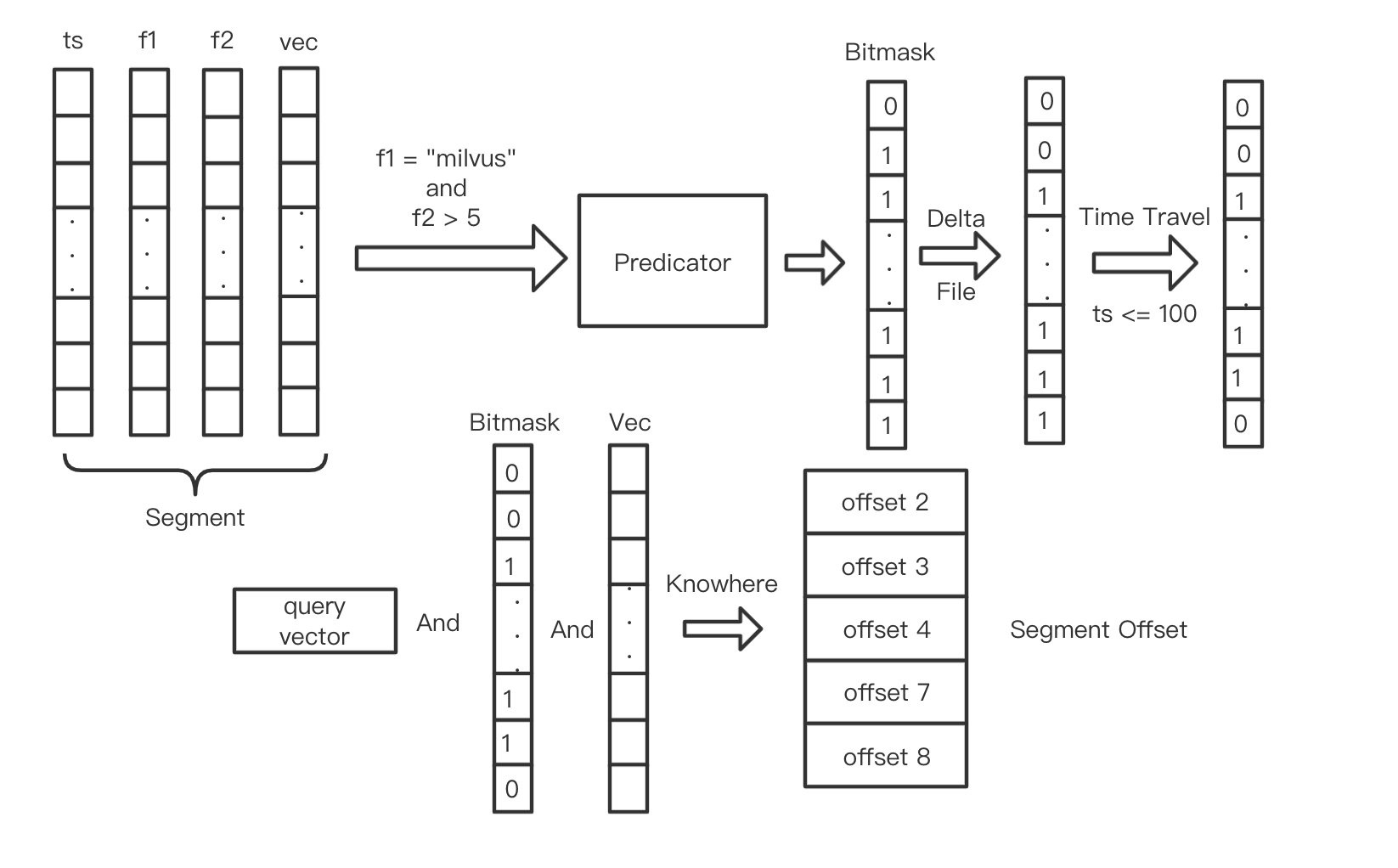
The bitmask roughly needs to go through the following 3 processing steps. First, a bitmask is generated through the query expression, then the bitmask is modified through the delete log in the DeltaFile, and finally, the bitmask is modified again according to the time-travel parameter and the timestamp field.
The final bitmask, together with the vector field and the target vector, participate in the approximate query and returns an array containing the positions of the Entities that meet the search conditions. For convenience, we named this array SegmentOffsets.
When the limit parameter of the Search is K, it means that only TopK results are needed. At this time, the length of SegmentOffsets is K. When doing a hybrid search, you can also specify output_field to retrieve the data of the corresponding Entity's Field.
It can be seen that segment offsets play a key role in segment processing. We need to calculate the segment offsets based on the approximate search on the vector and the filtering of the expression; we also need to extract the data of each Field in the corresponding entity of the Segment based on the offset.
We abstract the Stringfield Interface.
type StringField inteface {
extract(segmentOffsets []int32) []string
serialize() []bytes
deserialize([]bytes)
}
func Filter(expression string, field StringField) sgementOffsets []int32