...
3. data coordinator node picks a data node or multiple data nodes (according to the sharding number) to parse files, each file can be parsed into a segment or multiple segments.
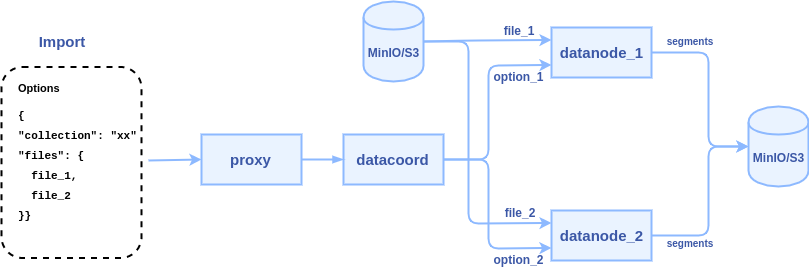
1. SDK Interfaces
The python API declaration:
...
- collection_name: the target collection name (required)
- partition_name: target partition name (optional)
- files: a list of files with row-based format or a dict of files with column-based format (required)
row-based files: ["file_1.json", "file_2.json"]
column-based files: {"id": "id.json", "vectors": "embeddings.npy"} - options: extra options in JSON format, for example: the MinIO/S3 bucket where the files come from (optional)
{"bucket": "mybucket"} - return a list of task ids
def get_import_state(task_id)
- task_id: id of an import task returned by import()
- return {finished: bool, row_count: integer}
Pre-defined format for import files
Assume we have a collection with 2 fields(one primary key and one vector field) and 5 rows:
...
| Code Block |
|---|
import(collection_name="test", files={"uid": "file_1.json", "vector": "file_2.npy"}) |
Error handling
The Import():
- Return error "File list is empty" if the row-based files list is empty
- For row-based files, all fields must be presented, otherwise, return the error "The field xxx is not provided"
- For column-based files, each field must correspond to a file, otherwise, return the error "The field xxx is not provided"
The get_import_state():
- Return error "File xxx doesn't exist" if could not open the file.
- The row count of each field must be equal, otherwise, return the error "Inconsistent row count between field xxx and xxx"
- If a vector dimension doesn't equal to field schema, return the error "Incorrect vector dimension for field xxx"
2. Proxy RPC Interfaces
| Code Block |
|---|
service MilvusService {
rpc Import(ImportRequest) returns (ImportResponse) {}
rpc GetImportState(GetImportStateRequest) returns (GetImportStateResponse) {}
}
message ImportRequest {
string collection_name = 1; // target collection
string partition_name = 2; // target partition
bool row_based = 3; // the file is row-based or column-based
repeated string files = 4; // file paths to be imported
repeated common.KeyValuePair options = 5; // import options
}
message ImportResponse {
common.Status status = 1;
repeated int64 tasks = 2; // id array of import tasks
}
message GetImportStateRequest {
int64 task = 1; // id of animport task
}
message GetImportStateResponse {
common.Status status = 1;
bool finished = 2; // is this import task finished or not
int64 row_count = 3; // if the task is finished, this value is how many rows are imported. if the task is not finished, this value is how many rows are parsed.
} |
3. Datacoord RPC interfaces
The declaration of import API in datacoord RPC:
| Code Block |
|---|
service DataCoord {
rpc Import(milvus.ImportRequest) returns (milvus.ImportResponse) {}
rpc GetImportState(milvus.GetImportStateRequest) returns (milvus.GetImportStateResponse) {}
rpc CompleteImport(ImportResult) returns (common.Status) {}
}
message ImportResult {
common.Status status = 1;
repeated int64 segments = 2; // id array of new sealed segments
int64 row_count = 3; // how many rows are imported by this task
} |
4. Datanode interfaces
The declaration of import API in datanode RPC:
| Code Block |
|---|
service DataNode {
rpc Import(milvus.ImportRequest) returns(common.Status) {}
} |
5. Bulk Load task Assignment
There is a background knowledge that the inserted data shall be hashed into shards. Bulk load shall follow the same convention. There are two policy we can choose to satisfy this requirement:
...
Considering the efficiency and flexibility, we shall implement option 1.
6. Result segments availability
By definition, the result segments shall be available altogether. Which means there shall be no intermediate state for loading.
To achieve this property, the segments shall be marked as "Loading" state and be invisible before the whole loading procedure completes.
7. Bulk Load with Delete
Constraint: The segments generated by Bulk Load shall not be affected by delete operations before the whole procedure is finished.
An extra attribute may be needed to mark the Load finish ts and all delta log before this ts shall be ignored.
8. Bulk Load and Query Cluster
After the load is done, the result segments needs to be loaded if the target collection/partition is loaded.
...
- Allow adding segments without removing one
- Bring target segments online atomically.
9. Bulk Load and Index Building
The current behavior of query cluster is that if there is an index built for the collection, the segments will not be loaded(as sealed segment) before the index is built.
...
Constraint: The bulk load procedure shall include the period of index building of the result segments
10. Bulk Load as a tool
The bulk load logic can be extracted into a tool to run outside of Milvus process. It shall be implemented in the next release.
...