...
- client calls insert() to transfer data to Milvus proxy node
- proxy split the data in do multiple parts according to sharding number of the collection
- proxy construct constructs a message packet for each part , and send the message packets into the Pulsar service
- data nodes pull the message packets from the Pulsar service, each data node pull a packet
- data nodes persist data into segment when flush() action is triggered
...
2. proxy node passes the file paths to data coordinator node
3. data coordinator pick node picks a data node or multiple data node nodes (according to the files countsharding number) to parse files, each file can be parsed to into a segment or multiple segments.
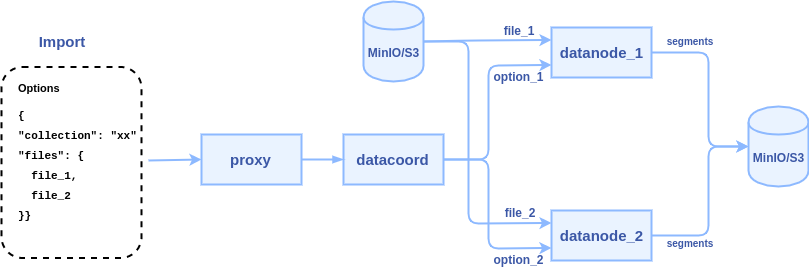 Some points to consider:
Some points to consider:
- JSON format is flexible, ideally, the import API ought to parse user's JSON files without asking user to reformat their files according to a strict rule.
- Users can store scalar fields and vector fields in a JSON file, with row-based or column-based. The import() API can support both of them.
Store scalar fields and vector field data in a JSON file with row-based example:
| Code Block |
|---|
{
"table": {
"rows": [
{"id": 1, "year": 2021, "vector": [1.0, 1.1, 1.2]},
{"id": 2, "year": 2022, "vector": [2.0, 2.1, 2.2]},
{"id": 3, "year": 2023, "vector": [3.0, 3.1, 3.2]}
]
}
} |
Store scalar fields and vector field data in a JSON file with column-based example:
| Code Block |
|---|
{
"table": {
"columns": [
"id": [1, 2, 3],
"year": [2021, 2022, 2023],
"vector": [
[1.0, 1.1, 1.2],
[2.0, 2.1, 2.2],
[3.0, 3.1, 3.2]
]
]
}
} |
- Numpy file is a binary format, we only treat it as vector data. Each Numpy file represents a vector field.
- Transferring a large file from client to server proxy to datanode is time-consume work and occupies too much network bandwidth, we will ask users to upload data files to MinIO/S3 where the datanode can access directly. Let the datanode read and parse files from MinIO/S3.
- Users may store scalar fields and vector fields in different format files. For example, store scalar fields in JSON files and store vector fields in Numpy files.
- The parameter of import API is easy to expand in future.
SDK Interfaces
Based on the several points, we choose a JSON object as a parameter of python import() API, the API declaration will be like this:
def import(options)
...
SDK Interfaces
The API declaration:
def import(collection_name, files, bucket=None)
| Code Block |
|---|
{
"data_source": { // required
"type": "minio", // required, "minio" or "s3", case insensitive
"address": "localhost:9000", // optional, milvus server will use its minio/s3 configuration if without this value
"accesskey_id": "minioadmin", // optional, milvus server will use its minio/s3 configuration if without this value
"accesskey_secret": "minioadmin", // optional, milvus server will use its minio/s3 configuration if without this value
"use_ssl": false, // optional, milvus server will use its minio/s3 configuration if without this value
"bucket_name": "aaa" // optional, milvus server will use its minio/s3 configuration if without this value
},
"internal_data": { // optional, external_data or internal_data. (external files include json, npy, etc. internal files are exported by milvus)
"path": "xxx/xxx/xx", // required, relative path to the source storage where store the exported data
"collections_mapping": { // optional, give a new name to collection during importing
"coll_a": "coll_b", // collection name mapping, key is the source collection name, value is a new collection name
"coll_c": "coll_d"
}
},
"external_data": { // optional, external_data or internal_data. (external files include json, npy, etc. internal files are exported by milvus)
"target_collection": "xxx", // required, target collection name
"chunks": [{ // required, chunk list, each chunk can be import as one segment or split into multiple segments
"files": [{ // required, files that provide data of a chunk
"path": "xxxx / xx.json", // required, relative path under the storage source defined by DataSource, currently support json/npy
"type": "row_based", // required for json file, "row_based" or "column_based", tell milvus how to parse this json file, case insensitive
"from": 0, // optional, import part of the file from a number
"to": 1000, // optional, import part of the file end by a number
"fields_mapping": { // optional, specify the target fields which should be imported. Milvus will import all fields if this list is empty
"table.rows.id": "uid", // field name mapping, tell milvus how to insert data to correct field, key is a json node path, value is a field name of the collection. If the file is numpy format, the key is a field name of the collection same with value.
"table.rows.year": "year",
"table.rows.vector": "vector"
}
}]
}
],
"default_fields": { // optional, use default value to fill some fields
"age": 0, // key is a field name, value is default value of this field, can be number or string
"weight": 0.0
}
}
} |
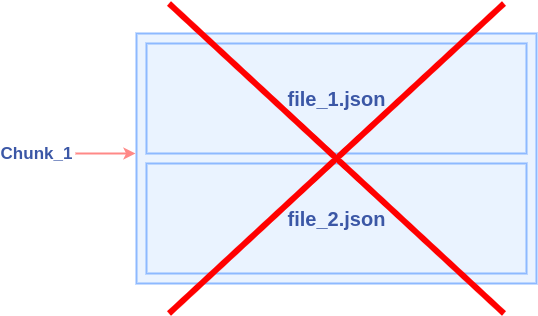
The following chart shows what is "chunk":
...
Note: A chunk can be represented by one file or multiple files. But multiple files should represent different columns, not different rows.
Key fields of the JSON object:
- "data_source": contains the address and login methods of MinIO/S3. If the address and login methods are not provided, Milvus will use its MinIO/S3 configurations.
- "internal_data": reserved field for collection clone and database clone, not available in the first stage. It requires another new API export().
- "external_data": for importing data from user's files. Tell datanode where to read the data files and how to parse them.
How to pass this parameter in different situations:
Assume there is a collection named "TEST" with these fields:
| Code Block |
|---|
{"uid":INT64, "year":INT32, "age":INT8, "embedding":FLOAT_VECTOR} |
For the following situations:
User has some JSON files store data with the row-based format: file_1.json, file_2.json.
| Code Block |
|---|
{
"data": {
"rows": [
{"id": 1, "year": 2021, "vector": [1.0, 1.1, 1.2]},
{"id": 2, "year": 2022, "vector": [2.0, 2.1, 2.2]},
{"id": 3, "year": 2023, "vector": [3.0, 3.1, 3.2]}
]
}
} |
The "options" could be:
| Code Block |
|---|
{
"data_source": {
"type": "Minio",
"address": "localhost:9000",
"accesskey_id": "minioadmin",
"accesskey_secret": "minioadmin",
"use_ssl": false,
"bucket_name": "mybucket"
},
"external_data": {
"target_collection": "TEST",
"chunks": [{
"files": [{
"path": "xxxx/file_1.json",
"type": "row_based",
"fields_mapping": {
"table.rows.id": "uid",
"table.rows.year": "year",
"table.rows.vector": "vector"
}
}]
},
{
"files": [{
"path": "xxxx/file_2.json",
"type": "row_based",
"fields_mapping": {
"table.rows.id": "uid",
"table.rows.year": "year",
"table.rows.vector": "vector"
}
}]
}
],
"default_fields": {
"age": 0
}
}
} |
User has some JSON files store data with the column-based format: file_1.json, file_2.json.
| Code Block |
|---|
{
"table": {
"columns": [
"id": [1, 2, 3],
"year": [2021, 2022, 2023],
"vector": [
[1.0, 1.1, 1.2],
[2.0, 2.1, 2.2],
[3.0, 3.1, 3.2]
]
]
}
} |
The "options" could be:
| Code Block |
|---|
{
"data_source": {
"type": "Minio",
"address": "localhost:9000",
"accesskey_id": "minioadmin",
"accesskey_secret": "minioadmin",
"use_ssl": false,
"bucket_name": "mybucket"
},
"external_data": {
"target_collection": "TEST",
"chunks": [{
"files": [{
"path": "xxxx/file_1.json",
"type": "column_based",
"fields_mapping": {
"table.columns.id": "uid",
"table.columns.year": "year",
"table.columns.vector": "vector"
}
}]
},
{
"files": [{
"path": "xxxx/file_2.json",
"type": "column_based",
"fields_mapping": {
"table.columns.id": "uid",
"table.columns.year": "year",
"table.columns.vector": "vector"
}
}]
}
],
"default_fields": {
"age": 0
}
}
} |
...
| Code Block |
|---|
{
"table": {
"columns": [
"id": [1, 2, 3],
"year": [2021, 2022, 2023],
"age": [23, 34, 21]
]
]
}
} |
The "options" could be:
| Code Block |
|---|
{
"data_source": {
"type": "Minio",
"address": "localhost:9000",
"accesskey_id": "minioadmin",
"accesskey_secret": "minioadmin",
"use_ssl": false,
"bucket_name": "mybucket"
},
"external_data": {
"target_collection": "TEST",
"chunks": [{
"files": [{
"path": "xxxx/file_1.json",
"type": "column_based",
"fields_mapping": {
"table.columns.id": "uid",
"table.columns.year": "year",
"table.columns.age": "age"
}
}]
},
{
"files": [{
"path": "xxxx/file_2.npy",
"fields_mapping": {
"vector": "vector"
}
}]
}
]
}
} |
...
Proxy RPC Interfaces
The declaration of import API in proxy RPC:
...