...
- client calls insert() to transfer data to Milvus proxy node
- proxy split the data in do multiple parts according to sharding number of the collection
- proxy construct a message packet for each part, and send the message packets into Pulsar service
- data nodes pull the message packets from the Pulsar service, each data node pull a packet
- data nodes persist data into segment when flush() action is triggered
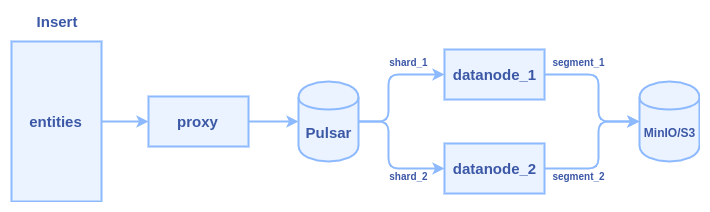
Typically, it cost several hours to insert one billion entities with 128-dimensional vectors. Lots of time is wasted in two major areas: network transmission and Pulsar management.
We can see there are at least three times network transmission in the process: 1) client => proxy 2) proxy => pulsar 3) pulsar => data node
...
3. data coordinator pick a data node or multiple data node (according to the files count) to parse files, each file can be parsed to a segment or multiple segments.
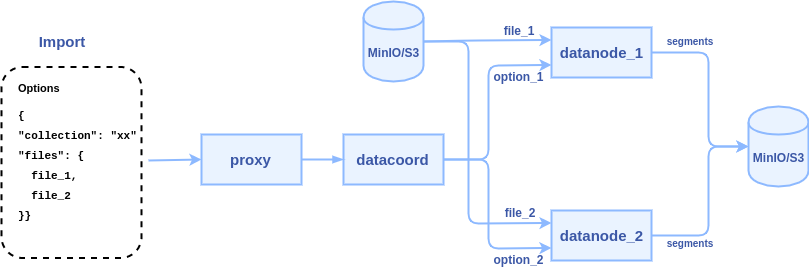
Some points to consider:
- JSON format is flexible, ideally, the import API ought to parse user's JSON files without asking user to reformat their files according to a strict rule.
- Users can store scalar fields and vector fields in a JSON file, with row-based or column-based. The import() API can support both of them.
...