...
Note: the "state" could be "pending", "started", "downloaded", "parsed", "persisted", "completed"completed, "failed"
Pre-defined format for import files
...
| Code Block |
|---|
{
"rows":[
{"uid": 101, "vector": [1.1, 1.2, 1.3, 1.4]},
{"uid": 102, "vector": [2.1, 2.2, 2.3, 2.4]},
{"uid": 103, "vector": [3.1, 3.2, 3.3, 3.4]},
{"uid": 104, "vector": [4.1, 4.2, 4.3, 4.4]},
{"uid": 105, "vector": [5.1, 5.2, 5.3, 5.4]},
]
} |
Call import() to import the file:
...
| Code Block |
|---|
import(collection_name="test", row_based=false, files=["file_1.json", "vector.npy"]) |
Note: for column-based, we don't support multiple json files, all columns should be stored in one json file. If user use a numpy file to store vector field, then other scalar fileds should be stored in one json file.
Error handling
The Import():
- Return error "Collection doesn't exist" if the target collection doesn't exist
- Return error "Party Partition doesn't exist" if the target partition doesn't exist
- Return error "Bucket doesn't exist" if the target bucket doesn't exist
- Return error "File list is empty" if the row-based files list is empty
- ImportTask pending list has limit size, if a new import request exceed the limit size, return error "Import task queue max size is xxx, currently there are xx pending tasks. Not able to execute this request with x tasks."
The get_import_state():
- Return error "File xxx doesn't exist" if could not open the file.
- All For row-based files, all fields must be presented, otherwise, return the error "The field xxx is not provided"
- For columnrow-based json files, each field must correspond to a file, otherwise, return the error "The field xxx is not provided"return "not a valid row-based json format, the key rows not found" if could not find the "rows" node
- For column-based files, if a vector field is duplicated in numpy file and json file, return the error "The field xxx is duplicated
...
- Return error "File xxx doesn't exist" if could not open the file. json parse error: xxxxx" if encounter illegal json format
- The row count of each field must be equal, otherwise, return the error "Inconsistent row count between field xxx and xxx". (all segments generated by this file will be abandoned)
- If a vector dimension doesn't equal to field schema, return the error "Incorrect vector dimension for field xxx". (all segments generated by this file will be abandoned)
- If a data file size exceed 1GB, return error "Data file size must be less than 1GB"
- If an import task is no response for more than 6 hours, it will be marked as failed
- If datanode is crashed or restarted, the import task on it will be marked as failed
...
| Code Block |
|---|
service MilvusService {
rpc Import(ImportRequest) returns (ImportResponse) {}
rpc GetImportState(GetImportStateRequest) returns (GetImportStateResponse) {}
}
message ImportRequest {
string collection_name = 1; // target collection
string partition_name = 2; // target partition
bool row_based = 3; // the file is row-based or column-based
repeated string files = 4; // file paths to be imported
repeated common.KeyValuePair options = 5; // import options, bucket, etc.
}
message ImportResponse {
common.Status status = 1;
repeated int64 tasks = 2; // id array of import tasks
}
message GetImportStateRequest {
int64 task = 1; // id of an import task
}
enum ImportState {
ImportPending = 0;
ImportFailed = 1;
ImportDownloaded = 2;
ImportParsed = 3;
ImportPersisted = 4;
ImportCompleted = 5;
}
message GetImportStateResponse {
common.Status status = 1;
ImportState state = 2; // is this import task finished or not
int64 row_count = 3; // if the task is finished, this value is how many rows are imported. if the task is not finished, this value is how many rows are parsed. return 0 if failed.
repeated int64 id_list = 4; // auto generated ids if the primary key is autoid
repeated common.KeyValuePair infos = 5; // more informations about the task, progress percent, file path, failed reason, etc.
} |
The call chain of import worflow:
...
} |
3. Rootcoord RPC interfaces
...
| Code Block |
|---|
service RootCoord {
rpc Import(milvus.ImportRequest) returns (milvus.ImportResponse) {}
rpc GetImportState(milvus.GetImportStateRequest) returns (milvus.GetImportStateResponse) {}
rpc ReportImport(ImportResult) returns (common.Status) {}
}
message ImportResult {
common.Status status = 1;
int64 task_id = 2; // id of the task
common.ImportState state = 3; // state of the task
repeated int64 segments = 4; // id array of new sealed segments
repeated int64 auto_ids = 5; // auto-generated ids for auto-id primary key
int64 row_count = 6; // how many rows are imported by this task
repeated common.KeyValuePair infos = 7; // more informations about the task, file path, failed reason, etc.
} |
The call chain of import worflow:
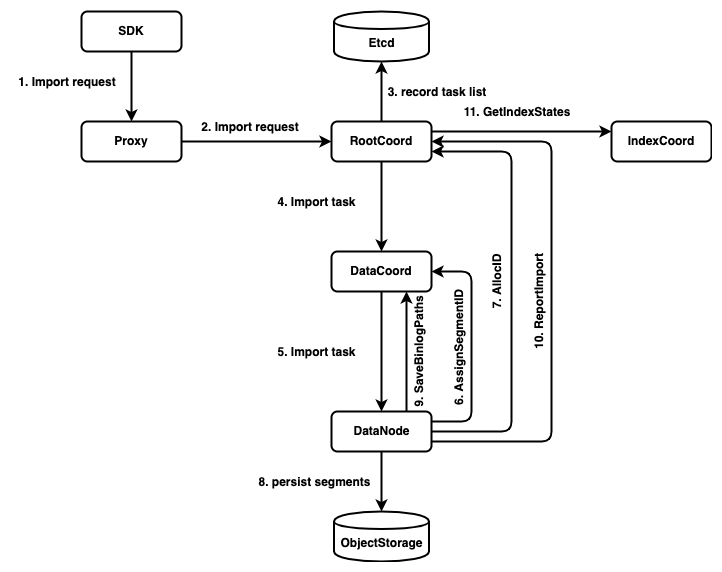
4. Datacoord RPC interfaces
...
| Code Block |
|---|
service DataCoord {
rpc Import(ImportTask) returns (ImportTaskResponse) {}
}
message ImportTask {
common.Status status = 1;
string collection_name = 2; // target collection
string partition_name = 3; // target partition
bool row_based = 4; // the file is row-based or column-based
int64 task_id = 5; // id of the task
repeated string files = 6; // file paths to be imported
repeated common.KeyValuePair infos = 7; // more informations about the task, bucket, etc.
}
message ImportTaskResponse {
common.Status status = 1;
int64 datanode_id = 2; // which datanode takes this task
} |
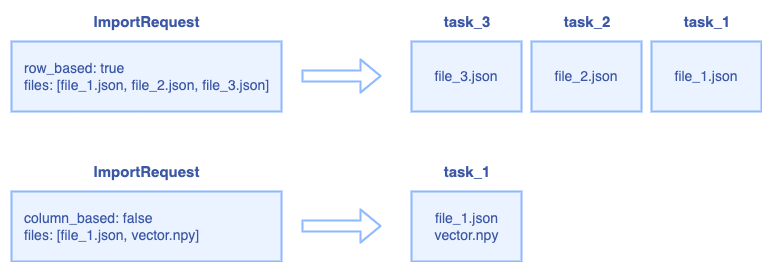
The relationship between ImportRequest and ImportTask:
For row-based request, the RootCoord splits the request into multiple ImportTask, each json file is a ImportTask.
For column-based request, all files will be regarded as one ImportTask.
5. Datanode interfaces
The declaration of import API in datanode RPC:
...
To achieve this property, the segments shall be marked as "LoadingImporting" state and be invisible before the whole loading procedure completes.
...