Current state: "Under DiscussionRejected"
ISSUE: #7210
PRs:
Keywords: arrow/column-based/row-based
Released: Milvus 2.0
Summary
...
What are we going to do?
Milvus 2.0 is a cloud-native and multi-language vector database, we use gRPC and pulsar to communicate among SDK and components.
In consideration of the data size, especially when inserting and search result returning, Milvus takes a lot of CPU cycles to do serialization and deserialization.
In this enhancement proposal, we suggest to adopt Apache Arrow as Milvus in-memory data format. Since in the field of big data, Apache Arrow has been a
factor standard for in-memory analytics. It specifies a standardized language-independent columnar memory format.
Motivation(required)
From a data perspective, Milvus mainly includes 2 data flows:
- Insert data flow
- Search data flow
Insert Data Flow
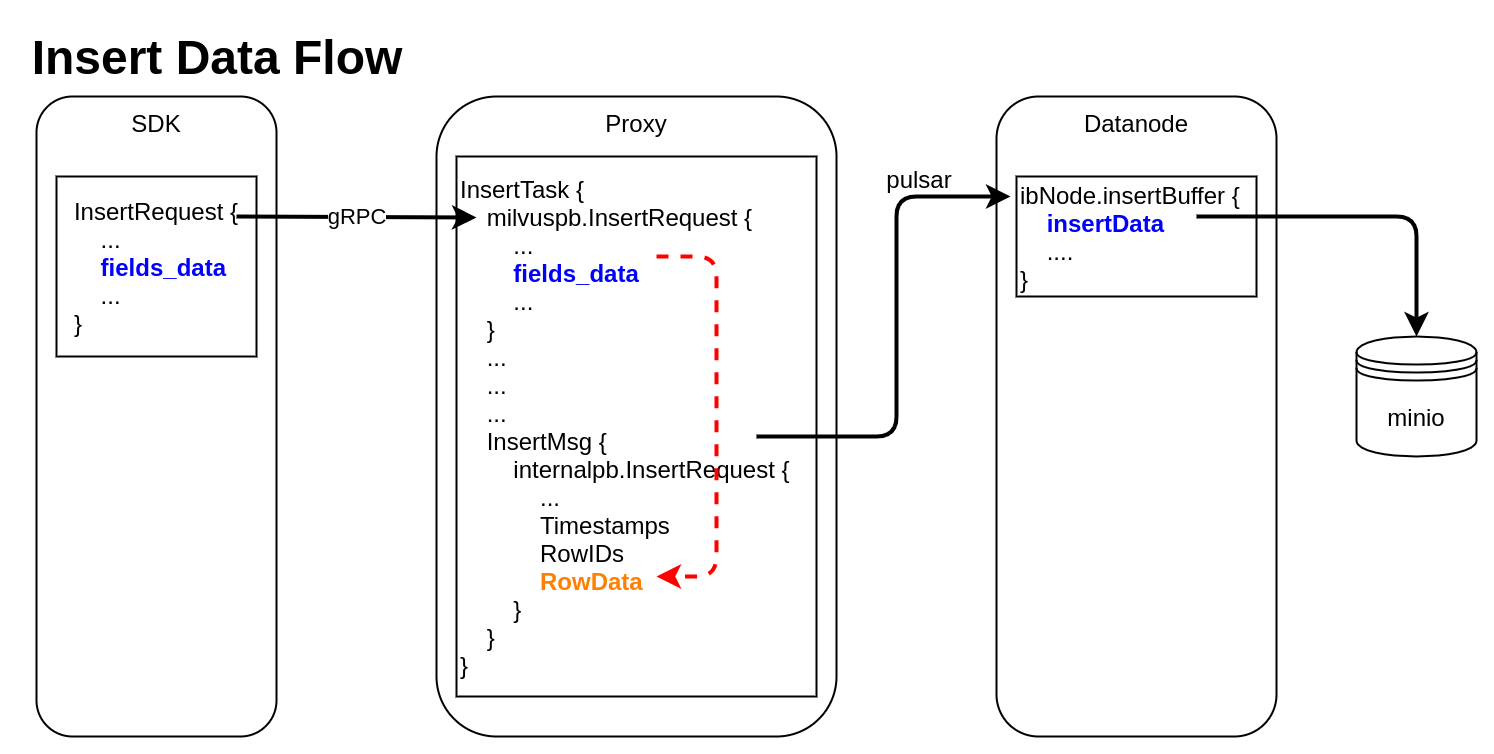
pymilvus creates a data insert request with
Motivation(required)
From data inspect, Milvus includes 2 data flows mainly: 1). Insert data flow 2). Search data flow
Insert Data Flow
pymilvus creates a data insert request with type milvuspb.InsertRequest (client/prepare.py::bulk_insert_param)
Code Block language text // grpc-proto/milvus.proto message InsertRequest { commoncommon.MsgBase base = 1; string string db_name = 2; stringstring collection_name = 3; string string partition_name = 4; repeated repeated schema.FieldData fields_data = 5; // fields' data repeated repeated uint32 hash_keys = 6; uint32 uint32 num_rows = 7; }Data is inserted into fields_data by column, schemapb.FieldData is defined as following:
Code Block // grpc-proto/schema.protomessage ScalarField {
oneofoneof data {
BoolArrayBoolArray bool_data = 1;
IntArrayIntArray int_data = 2;
LongArrayLongArray long_data = 3;
FloatArrayFloatArray float_data = 4;
DoubleArrayDoubleArray double_data = 5;
StringArrayStringArray string_data = 6;
BytesArrayBytesArray bytes_data = 7;
}
}
message VectorField {
int64int64 dim = 1;
oneofoneof data {
FloatArrayFloatArray float_vector = 2;
bytesbytes binary_vector = 3;
}
}
message FieldData {
DataTypeDataType type = 1;
stringstring field_name = 2;
oneofoneof field {
ScalarFieldScalarField scalars = 3;
VectorFieldVectorField vectors = 4;
}
int64int64 field_id = 5;
}
milvuspb.InsertRequest 被序列化后通过 is serialized and send via gRPC 发送
Proxy组件收到 Proxy receives milvuspb.InsertRequest,为他创建任务InsertTask,并把该任务加入到执行队列中, creates InsertTask for it, and adds this task into execution queue (internal/proxy/impl.go::Insert)InsertTask被执行,InsertTask.req中的 列存 数据被转换为 行存 数据,并存入另一个用于 Milvus 内部流转的消息请求internalpb.InsertRequest中InsertTask is executed, the column-based data stored in InsertTask.req is converted to row-based format, and saved into another internal message with type internalpb.InsertRequest (internal/proxy/task.go::transferColumnBasedRequestToRowBasedData)
internalpb.InsertRequest的定义如下:Code Block // internal/proto/internal.protomessage InsertRequest {
commoncommon.MsgBase base = 1;
stringstring db_name = 2;
stringstring collection_name = 3;
stringstring partition_name = 4;
int64int64 dbID = 5;
int64int64 collectionID = 6;
int64int64 partitionID = 7;
int64int64 segmentID = 8;
stringstring channelID = 9;
repeatedrepeated uint64 timestamps = 10;
repeatedrepeated int64 rowIDs = 11;
repeatedrepeated common.Blob row_data = 12; // row-based data
}
并为每行数据添加
rowID和timestamprowID and timestamp are added for each row data
Proxy把包含 Proxy encapsulates internalpb.InsertRequest 的InsertMsg发送到 into InsertMsg, and send it to pulsar channel 中Datanode 从 pulsar channel 中收到
InsertMsg,把数据重新恢复为 列式 存储,保存在内存结构InsertData中 receives InsertMsg from pulsar channel, restore data to column-based into structure InsertData (internal/datanode/flow_graph_insert_buffer_node.go::insertBufferNode::Operate)Code Block type InsertData struct {
mapData
map[FieldID]FieldData // field id to field data
Infos []BlobInfo
}
InsertData 以 parque Search Data Flow
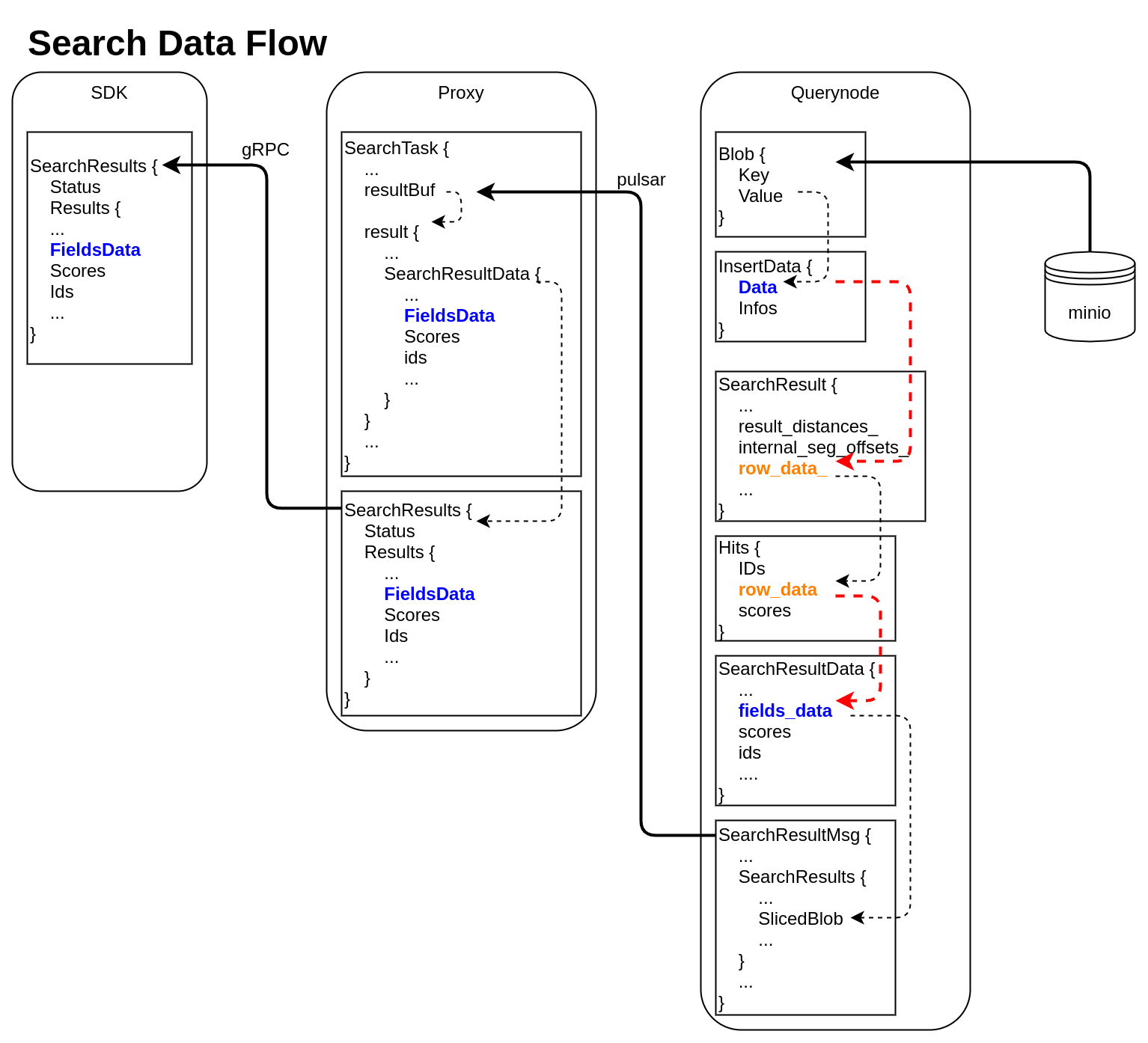
querynode reads segment's binlog files from Minio, and saves them into structure Blob (internal 在收到
LoadSegments请求后,会把segment对应的所有binlog文件从minio加载到内存,并放入内存数据结构Blob中 (internal/querynode/segment_loader.go::loadSegmentFieldsData)Code Block type Blob struct {
Key string // binlog file path
Value []byte // binlog file data
}
通常
querynode只加载标量数据,不加载向量数据,除非该向量列未建index。Blob里的数据经过反序列化后,提取出原始数据,存入InsertData数据结构中The data in Blob is deserialized, raw-data in it is saved into structure InsertData
querynode invokes search engine to get SearchResult (internal/query_node/query_collection.go::search)
Code Block language cpp // internal/core/src/common/Types.hstruct SearchResult {
...
public:
int64_t num_queries_;
int64_t topk_;
std::
vector<float>vector<float> result_distances_;
public:
void* segment_;
std::
vector<int64_t>vector<int64_t> internal_seg_offsets_;
std::
vector<int64_t>vector<int64_t> result_offsets_;
std::
vector<stdvector<std::
vector<char>>vector<char>> row_data_;
};
At this time, only "result_distances_ 和 - " and "internal_seg_offsets_ 被填入了数据。
- " of "SearchResult" are filled into data.
querynode reduces all SearchResult returned by segment, fetches all other fields' data, and saves them into "row_data_" with row-based format.
中 (internal/query_node/query_collection.go::reduceSearchResultsAndFillData)
querynode
对 organizes SearchResult again, and save them into structure milvus.Hits
Code Block // internal/proto/milvus.protomessage Hits {
repeated int64 IDs = 1;
repeated bytes row_data = 2;
repeated float scores = 3;
}
Row-based data saved in milvus.Hits 中的数据通过函数
translateHits转为 列存 数据 is converted to column-based data, and saved into schemapb.SearchResultData (internal/query_node/query_collection.go::translateHits)Code Block // internal/proto/schema.protomessage SearchResultData {
int64int64 num_queries = 1;
int64int64 top_k = 2;
repeatedrepeated FieldData fields_data = 3;
repeatedrepeated float scores = 4;
IDsIDs ids = 5;
repeatedrepeated int64 topks = 6;
}
schemapb.SearchResultData
被序列化后,封装为is serialized, encapsulated as internalpb.SearchResults
,并放入msgstream.SearchResultMsg,通过, saved into SearchResultMsg, and send into pulsar channel
发送(internal/query_node/query_collection.go::search)
Code Block // internal/proto/internal.protomessage SearchResults {
commoncommon.MsgBase base = 1;
commoncommon.Status status = 2;
stringstring result_channelID = 3;
stringstring metric_type = 4;
repeatedrepeated bytes hits = 5; // search result data
// schema.SearchResultsData inside
bytesbytes sliced_blob = 9;
int64int64 sliced_num_count = 10;
int64int64 sliced_offset = 11;
repeatedrepeated int64 sealed_segmentIDs_searched = 6;
repeatedrepeated string channelIDs_searched = 7;
repeatedrepeated int64 global_sealed_segmentIDs = 8;
}
proxy从 pulsar channel 中收集到所有querynode发送过来的msgstream.SearchResultMsg,反序列化得到Proxy collects all SearchResultMsg from querynodes, gets schemapb.SearchResultData
,再做一次归并,数据放入by deserialization, then gets milvuspb.SearchResults
,通过 gRPC 传回 SDKby reducing, finally send back to SDK visa gRPC. (internal/proxy/task.go::SearchTask::PostExecute)
Code Block // internal/proto/milvus.protomessage SearchResults {
commoncommon.Status status = 1;
schemaschema.SearchResultData results = 2;
}
SDK 收到 - SDK receives milvuspb. SearchResults
querynode 执行 search 请求,通过 CGO 调用 knowhere 搜索引擎,得到 SearchResultknowhere 返回的 SearchResult 中只有 querynode 在得到所有 segment 返回的 SearchResult 后,对结果做归并,并通过 internal_seg_offsets_ 得到其它输出列数据,并按 行存 格式写入 row_data_SearchResult 数据再次整理,存入数据结构 milvus.Hits 中Public Interfaces(optional)
Briefly list any new interfaces that will be introduced as part of this proposal or any existing interfaces that will be removed or changed.
Design Details(required)
Describe the new thing you want to do in appropriate detail. This may be fairly extensive and have large subsections of its own. Or it may be a few sentences. Use judgement based on the scope of the change.
## Compatibility, Deprecation, and Migration Plan(optional)
- What impact (if any) will there be on existing users?
- If we are changing behavior how will we phase out the older behavior?
- If we need special migration tools, describe them here.
- When will we remove the existing behavior?
...
Describe in few sentences how the MEP will be tested. We are mostly interested in system tests (since unit-tests are specific to implementation details). How will we know that the implementation works as expected? How will we know nothing broke?
Rejected Alternatives(optional)
If there are alternative ways of accomplishing the same thing, what were they? The purpose of this section is to motivate why the design is the way it is and not some other way.
References(optional)
...
- SearchResult
In above 2 data flows, we can see frequent format conversion between column-based data and row-based data (marked as RED dashed line).
If we use Arrow as all in-memory data format, we can:
- omit the serialization and deserialization between SDK and proxy
- remove all format conversion between column-based data and row-based data
- use Parquet as binlog file format, and write from arrow data directly
Proposal Benefit Analysis (optional)
Arrow memory usage, test following 3 scenarios used in Milvus:
| Data Type | Raw Data Size (Byte) | Array Array Buffer Size (Byte) |
|---|---|---|
| int64 | 80000 | 80000 |
| FixedSizeList (float32, dim = 128) | 5120000 | 5160064 |
| string (len = 512) | 5120000 | 5160064 |
For Scalar data, Arrow Array uses memory as same as raw data;
for vector data or string, Arrow Array uses few more memory than raw data (about 4 bytes for each row).
Give an example to illustrate the problems we will encounter if using Arrow.
During insert, after Proxy receives data, it will encapsulate the data into InsertMsg by line, and then send it to Datanode through Pulsar.
Splitting by line is based on two reasons:
- Each collection has two or more physical channels. Data insertion performance can be improved by inserting multiple channels at the same time.
- Pulsar limits the size of each InsertMsg
We tried 4 solutions, each has its own problems:
- Solution-1
After the Proxy receives the inserted data, it only creates one Arrow RecordBatch, encapsulates the data into InsertMsg by line, and then sends it to Datanode through Pulsar.
PROBLEM: There is no interface to read data item by item from Arrow RecordBatch. RecordBatch has a NewSlice interface, but the return value of NewSlice cannot do anything except print.
- Solution-2
After the Proxy receives the inserted data, it creates multiple Arrow RecordBatch in advance according to the size limit of Pulsar for InsertMsg. The data is serialized according to the RecordBatch, inserted into the InsertMsg, and then sent to the Datanode through Pulsar. Datanode combines multiple RecordBatch into one complete RecordBatch.
PROBLEM: Multiple RecordBatch can only be logically restored to one ArrowTable, but each column of data is physically discontinuous, so subsequent columnar operations cannot be performed.
- Solution-3
After the Proxy receives the inserted data, create multiple Arrow Array by field, instead of RecordBatch.
PROBLEM: The primitive unit of serialized data in Arrow is RecordBatch. Arrow does not provide interface to serialize Arrow Array.
- Solution-4
After the Proxy receives the inserted data, it creates multiple RecordBatch in advance according to the size limit of the Pulsar for InsertMsg. The data is serialized according to the RecordBatch and inserted into the InsertMsg, and then sent to the Datanode through Pulsar. The Datanode receives multiple RecordBatch, fetches the data from each column, and regenerates a new RecordBatch.
PROBLEM: There seems no advantages comparing with current implementation.
Summarize some limitations in the use of Arrow:
- Arrow data can only be serialized and deserialized by unit of RecordBatch;
- Cannot copy out row data from RecordBatch;
- RecordBatch must be regenerated after sending via pulsar.
Arrow is suitable for data analysis scenario (data is sealed and read only).
In Milvus, we need do data split and concatenate.
Arrow seems not a good choice for Milvus.
Design Details(required)
We divide this MEP into 2 stages, all compatibility changes will be achieved in Stage 1 before Milvus 2.0.0, other internal changes can be left later.
Stage 1
Update InsertRequest in milvus.proto, change Insert to use Arrow formatUpdate SearchRequest/Hits in milvus.proto, and SearchResultData in schema.proto, change Search to use Arrow formatUpdate QueryResults in milvus.proto, change Query to use Arrow format
Stage 2
Update Storage module to use GoArrow to write Parquet from Arrow, or read Arrow from Parquet directly, remove C++ Arrow.Remove all internal row-based data structure, including "RowData" in internalpb.InsertRequest, "row_data" in milvuspb.Hits, "row_data_" in C++ SearchResult.Optimize search result flow
Test Plan(required)
Pass all CI flows
References(optional)
https://arrow.apache.org/docs/
Arrow Test Code (Go)
| Code Block |
|---|
import (
"bytes"
"fmt"
"testing"
"github.com/apache/arrow/go/arrow"
"github.com/apache/arrow/go/arrow/array"
"github.com/apache/arrow/go/arrow/ipc"
"github.com/apache/arrow/go/arrow/memory"
)
const (
_DIM = 4
)
var pool = memory.NewGoAllocator()
func CreateArrowSchema() *arrow.Schema {
fieldVector := arrow.Field{
Name: "field_vector",
Type: arrow.FixedSizeListOf(_DIM, arrow.PrimitiveTypes.Float32),
}
fieldVal := arrow.Field{
Name: "field_val",
Type: arrow.PrimitiveTypes.Int64,
}
schema := arrow.NewSchema([]arrow.Field{fieldVector, fieldVal}, nil)
return schema
}
func CreateArrowRecord(schema *arrow.Schema, iValues []int64, vValues []float32) array.Record {
rb := array.NewRecordBuilder(pool, schema)
defer rb.Release()
rb.Reserve(len(iValues))
rowNum := len(iValues)
for i, field := range rb.Schema().Fields() {
switch field.Type.ID() {
case arrow.INT64:
vb := rb.Field(i).(*array.Int64Builder)
vb.AppendValues(iValues, nil)
case arrow.FIXED_SIZE_LIST:
lb := rb.Field(i).(*array.FixedSizeListBuilder)
valid := make([]bool, rowNum)
for i := 0; i < rowNum; i++ {
valid[i] = true
}
lb.AppendValues(valid)
vb := lb.ValueBuilder().(*array.Float32Builder)
vb.AppendValues(vValues, nil)
}
}
rec := rb.NewRecord()
return rec
}
func WriteArrowRecord(schema *arrow.Schema, rec array.Record) []byte {
defer rec.Release()
blob := make([]byte, 0)
buf := bytes.NewBuffer(blob)
// internal/arrdata/ioutil.go
writer := ipc.NewWriter(buf, ipc.WithSchema(schema), ipc.WithAllocator(pool))
defer writer.Close()
//ShowArrowRecord(rec)
if err := writer.Write(rec); err != nil {
panic("could not write record: %v" + err.Error())
}
err := writer.Close()
if err != nil {
panic(err.Error())
}
return buf.Bytes()
}
func ReadArrowRecords(schema *arrow.Schema, blobs [][]byte) array.Record {
iValues := make([]int64, 0)
vValues := make([]float32, 0)
for _, blob := range blobs {
buf := bytes.NewReader(blob)
reader, err := ipc.NewReader(buf, ipc.WithSchema(schema), ipc.WithAllocator(pool))
if err != nil {
panic("create reader fail: %v" + err.Error())
}
defer reader.Release()
rec, err := reader.Read()
if err != nil {
panic("read record fail: %v" + err.Error())
}
defer rec.Release()
for _, col := range rec.Columns() {
switch col.DataType().ID() {
case arrow.INT64:
arr := col.(*array.Int64)
iValues = append(iValues, arr.Int64Values()...)
case arrow.FIXED_SIZE_LIST:
arr := col.(*array.FixedSizeList).ListValues().(*array.Float32)
vValues = append(vValues, arr.Float32Values()...)
}
}
}
ret := CreateArrowRecord(schema, iValues, vValues)
ShowArrowRecord(ret)
return ret
}
func ReadArrowRecordsToTable(schema *arrow.Schema, blobs [][]byte) array.Table {
recs := make([]array.Record, 0)
for _, blob := range blobs {
buf := bytes.NewReader(blob)
reader, err := ipc.NewReader(buf, ipc.WithSchema(schema), ipc.WithAllocator(pool))
if err != nil {
panic("create reader fail: %v" + err.Error())
}
defer reader.Release()
rec, err := reader.Read()
if err != nil {
panic("read record fail: %v" + err.Error())
}
defer rec.Release()
recs = append(recs, rec)
}
table := array.NewTableFromRecords(schema, recs)
ShowArrowTable(table)
return table
}
func ShowArrowRecord(rec array.Record) {
fmt.Printf("\n=============================\n")
fmt.Printf("Schema: %v\n", rec.Schema())
fmt.Printf("NumCols: %v\n", rec.NumCols())
fmt.Printf("NumRows: %v\n", rec.NumRows())
//rowNum := int(rec.NumRows())
for i, col := range rec.Columns() {
fmt.Printf("Column[%d] %q: %v\n", i, rec.ColumnName(i), col)
}
}
func ShowArrowTable(tbl array.Table) {
fmt.Printf("\n=============================\n")
fmt.Printf("Schema: %v\n", tbl.Schema())
fmt.Printf("NumCols: %v\n", tbl.NumCols())
fmt.Printf("NumRows: %v\n", tbl.NumRows())
for i := 0; i < int(tbl.NumCols()); i++ {
col := tbl.Column(i)
fmt.Printf("Column[%d] %s: %v\n", i, tbl.Schema().Field(i).Name, col.Data().Chunks())
}
}
func TestArrowIPC(t *testing.T) {
schema := CreateArrowSchema()
rec0 := CreateArrowRecord(schema, []int64{0}, []float32{0,0,0,0})
rec1 := CreateArrowRecord(schema, []int64{1,2,3}, []float32{1,1,1,1,2,2,2,2,3,3,3,3})
blob0 := WriteArrowRecord(schema, rec0)
blob1 := WriteArrowRecord(schema, rec1)
ReadArrowRecords(schema, [][]byte{blob0, blob1})
ReadArrowRecordsToTable(schema, [][]byte{blob0, blob1})
} |