...
In this MEP, we put forward an IDMAP/BinaryIDMAP Enhancement proposal that let knowhere index type IDMAP/BinaryIDMAP accept to hold an external vector data pointer instead of adding real vector data in.
...
The only reasonable use scenario for IDMAP/BinaryIDMAP is for growing segment. But creating vector index is a resource consuming operation, because it involves all Milvus nodes in -- an index file is created by index node, saved by data node and loaded by query node, meanwhile proxy / if create an IDMAP/BinaryIDMAP index in a normal way, it will consume lots of resources, because it will involve index node (to create index file), data node (to save index file to S3) and rootcoord / indexcoord / datacoord / querycoord are also involved (to coordinate all these operations).
So currently in Milvus , it uses following 2 strategies for growing segment searching:
...
The advantage of this solution is resource saving, except query node, no other nodes will be involved in; while the shortcoming is code duplication. See following "Search Flow" chart, `FloatSearchBruteForce` and `BinarySearchBruteForce` are copied from knowhere::IDMAP and knowhere::BinaryIDMAP. More code duplicated, more effort on code maintenance/BinaryIDMAP's Query() and modified a little. This will introduce more code maintenance effort. And when realize new feature on IDMAP/BinaryIDMAP in Knowhere, such as range search, same work need be re-done on Milvus segcorewe have to alto copy these codes implementation to Milvus.
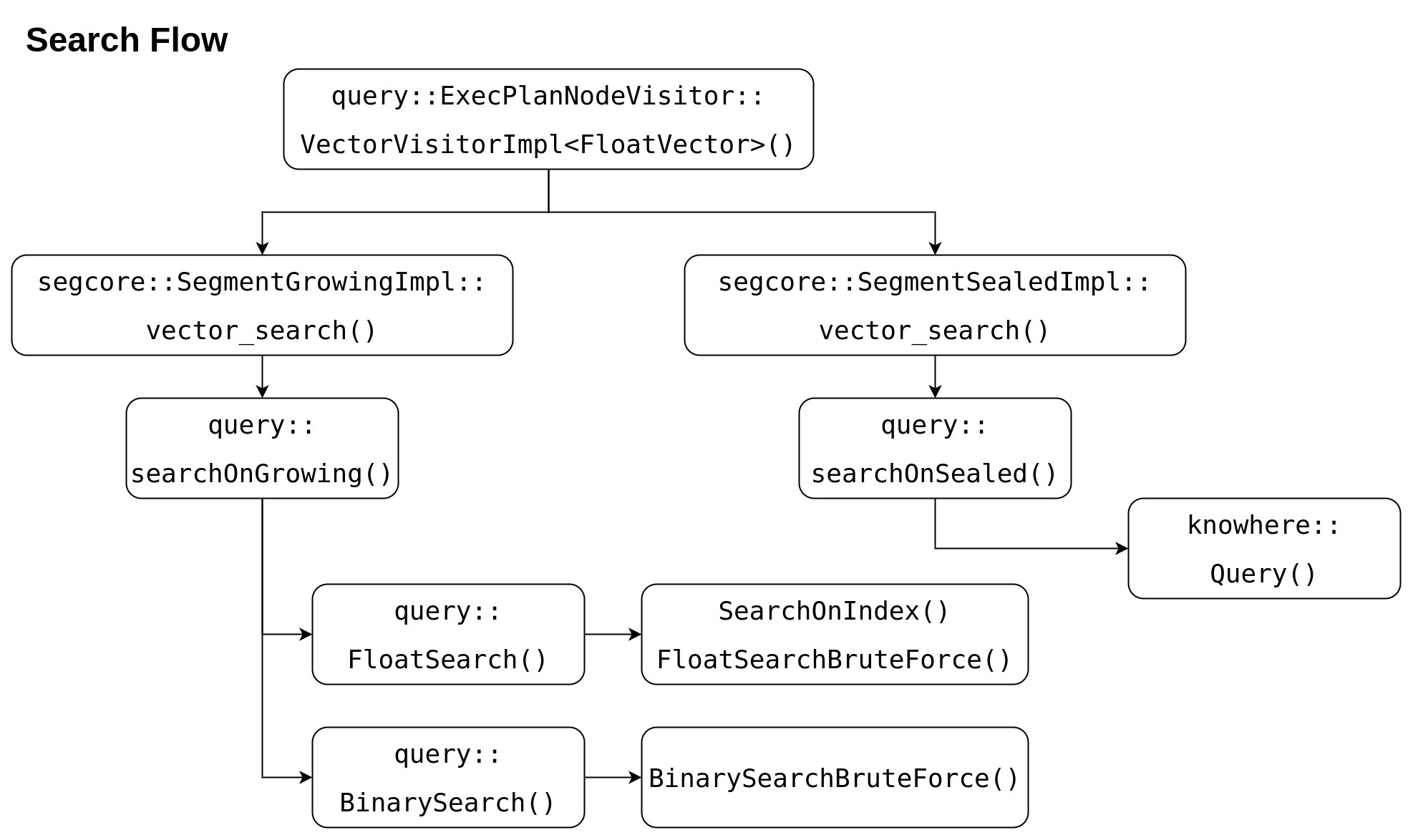
This is why enhanced A good solution is to enhance IDMAP/BinaryIDMAP is proposed. For enhanced IDMAP/BinaryIDMAP, vector data is not really added , not to add real vector data in, but only set let index to hold an external vector data pointer. User should need guarantee that the memory is contiguous and safe.
...